
Pandasの explode メソッド について詳しく解説します。
これは、DataFrameやSeriesに含まれる リスト形式の要素を行に展開する ときに使う便利なメソッドです。
特に、データが「ネストされたリスト」や「複数の値を1セルに持つような構造」になっているときに役立ちます。
目次
基本の動作
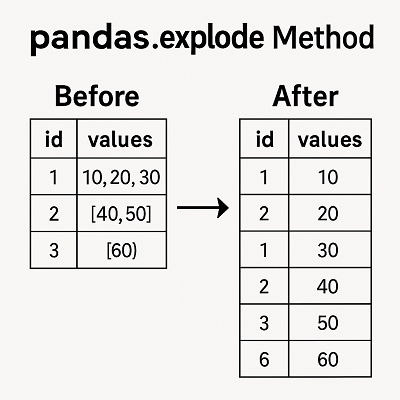
explode は、指定した列(または複数列)の リスト・タプル・セット を 行ごとに展開 します。
他の列は繰り返されるので、表形式の整形に使いやすいです。
例:単一列の展開
import pandas as pd
df = pd.DataFrame({
"id": [1, 2, 3],
"values": [[10, 20, 30], [40, 50], [60]]
})
print(df)
explode を使うと
df_exploded = df.explode("values")
print(df_exploded)
values 列が行に展開され、それに対応する id が繰り返されています。
複数列に対して explode
Pandas 1.3.0 以降では、複数列を同時に展開できます。
リストの「長さ」が一致している必要があります。
df = pd.DataFrame({
"id": [1, 2],
"A": [[10, 20], [30, 40]],
"B": [["x", "y"], ["z", "w"]]
})
print(df.explode(["A", "B"]))
特徴と注意点
- スカラーやNaNはそのまま残る
- リストじゃない値は展開されず、そのまま保持されます。
- NaN もそのまま残ります。
- インデックスは維持される
- 展開後も元のインデックスが維持されるので、必要なら
reset_index(drop=True)で振り直します。
df_exploded.reset_index(drop=True, inplace=True) - 展開後も元のインデックスが維持されるので、必要なら
- リストの長さが揃っていない場合(複数列explode時)はエラーになります。
片方がスカラ値、片方がリスト、のようなケースでは不整合が生じます。
よくある活用シーン
- JSONやAPIのレスポンスなど、リスト形式で返ってくるデータの正規化
- タグ・カテゴリなど「1セルに複数値」が入っているデータの整形
- 機械学習の前処理(特徴量を1行1データに変換)
他の方法との比較
apply(pd.Series)
→ リストを列に展開する(横方向)explode
→ リストを行に展開する(縦方向)
まとめ
explodeは リストを行方向に展開 するメソッド- 単一列だけでなく複数列にも対応(Pandas 1.3.0以降)
- インデックスは保持されるので、必要に応じて
reset_index() - データ整形、前処理、正規化にとても便利
以上、PythonのPandasのexplodeメソッドについてでした。
最後までお読みいただき、ありがとうございました。







