

ここでは Pandasでの正規化(Normalization)と標準化(Standardization)の違い、使い分け、実装方法、そして実務的な活用例まで、詳しく解説します。
目次
正規化(Normalization)とは
データを0~1の範囲などにスケーリングする方法です。
代表的なのが「Min-Maxスケーリング」です。
- 数式
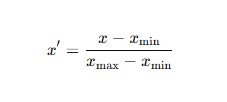
- 特徴
- 値がすべて 0~1 の範囲に収まる。
- 元の分布の形を保持する。
- 外れ値(outlier)に弱い。
よく使う場面
- ニューラルネットワークや距離ベースのアルゴリズム(KNN, K-meansなど)。
- 画像処理(ピクセルを0~255から0~1に正規化)。
標準化(Standardization)とは
データを平均0、標準偏差1に変換する方法です。
- 数式
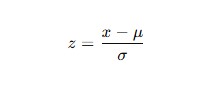
- 特徴
- 平均が0、分散が1になる。
- 外れ値の影響を受けにくい(正規化よりもロバスト)。
- 正規分布に近いデータでは特に有効。
よく使う場面
- 線形回帰、ロジスティック回帰、SVMなど、データの分布を前提にするアルゴリズム。
- PCA(主成分分析)の前処理。
Pandasでの実装方法
正規化(Min-Maxスケーリング)
import pandas as pd
# ダミーデータ
df = pd.DataFrame({
'A': [10, 20, 30, 40, 50],
'B': [5, 15, 25, 35, 45]
})
# Min-Max 正規化
df_norm = (df - df.min()) / (df.max() - df.min())
print(df_norm)
標準化(Zスコア変換)
# Zスコア標準化
df_std = (df - df.mean()) / df.std()
print(df_std)
Scikit-learnとの組み合わせ
実務では、Pandasだけでなく scikit-learnのMinMaxScalerやStandardScaler を使うのが一般的です。
# ライブラリのインポート
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# サンプルデータを作成
df = pd.DataFrame({
'A': [10, 20, 30, 40, 50],
'B': [5, 15, 25, 35, 45]
})
print("=== 元データ ===")
print(df)
# Min-Max 正規化
scaler = MinMaxScaler()
df_norm = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print("\n=== Min-Max 正規化 (0~1にスケーリング) ===")
print(df_norm)
# 標準化(Zスコア変換)
scaler = StandardScaler()
df_std = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print("\n=== 標準化(平均0, 標準偏差1に変換) ===")
print(df_std)
- メリット:学習データにfitし、テストデータにも同じ変換を適用できる(リーク防止)。
- 機械学習パイプラインと統合しやすい。
どちらを使うべきか?
- 正規化(Normalization)
→ 値を0~1に揃えたいとき(画像、距離計算、ニューラルネットワーク系)。 - 標準化(Standardization)
→ 統計解析や線形モデルに使いたいとき(回帰、PCA、SVMなど)。
実務的には、
- 距離ベース → 正規化
- 分布ベース → 標準化
と覚えると便利です。
まとめ
- 正規化:0~1の範囲に収める(Min-Max)。
- 標準化:平均0・標準偏差1に変換(Zスコア)。
- Pandasでも簡単に書けるが、実務は
sklearnで行うのが安全。 - モデルやアルゴリズムの特性によって使い分けが重要。
以上、Pandasの正規化・標準化についてでした。
最後までお読みいただき、ありがとうございました。







