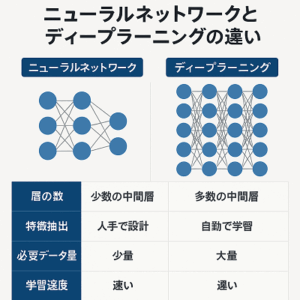
Pythonを使用したディープラーニングによる音声認識は非常に可能であり、現代のテクノロジーの中でも重要な分野の一つです。
このプロセスを理解するためには、以下の要素について考慮する必要があります。
音声認識とは
音声認識は、人間の話す言葉をテキストに変換するプロセスです。
これは、音声指示の理解、自動翻訳、音声からテキストへの変換など、多くのアプリケーションで使用されています。
ディープラーニングの役割

ディープラーニングは、音声認識の精度を大幅に向上させることができる強力なツールです。
ニューラルネットワーク、特にリカレントニューラルネットワーク(RNN)やその変種であるLSTM(Long Short-Term Memory)ネットワークは、音声の時間的特性を扱うのに適しています。
音声認識のプロセス
音声認識のプロセスは大まかに以下のステップに分けられます。
- 音声信号の前処理:
- 音声信号のノイズ除去
- 特徴抽出(MFCCs、スペクトログラムなど)
- ディープラーニングモデルの訓練:
- 大量のラベル付き音声データを用いた訓練
- モデルの構造(RNN、LSTM、Convolutional Neural Networksなど)
- デコーディングと変換:
- ニューラルネットワークの出力をテキストに変換
- 言語モデルを使用した誤りの修正
Pythonとディープラーニングライブラリ
TensorFlow
TensorFlowはGoogleによって開発されたオープンソースのライブラリで、様々な種類のディープラーニングモデルに対応しています。
- 特徴:
- 強力な計算グラフ構築機能。
- 大規模なデータセットやモデルに対応。
- TPU(Tensor Processing Unit)を含む多様なハードウェアでの最適化。
- 音声認識への適用:
- 時系列データ処理に適したRNN、LSTMのサポート。
- 音声データの前処理と特徴抽出を容易に行える。
Keras
KerasはTensorFlow上で動作する高レベルのニューラルネットワークAPIで、使いやすさが特徴です。
- 特徴:
- 初心者にも扱いやすい直感的なAPI。
- モデルの迅速なプロトタイピングが可能。
- TensorFlow、Theano、CNTKなど複数のバックエンドをサポート。
- 音声認識への適用:
- カスタムレイヤーや損失関数を簡単に追加。
- 様々なRNNコンポーネントを利用して時系列データを扱う。
PyTorch
Facebookによって開発されたPyTorchは、研究コミュニティで特に人気があります。
- 特徴:
- 動的計算グラフ(Define-by-Runアプローチ)。
- Pythonicな設計で直感的な操作が可能。
- 強力なコミュニティサポートと豊富なライブラリ。
- 音声認識への適用:
- 効率的なGPU加速と自動微分機能。
- カスタムRNNやCNNモデルの構築に適している。
実際の実装

音声認識の具体的な実装には、次の手順が含まれます。
データセットの収集
- 公開されている音声データセット(例:LibriSpeech, Common Voice)の使用
- データの前処理と正規化
モデルの設計と訓練
- ニューラルネットワークのアーキテクチャの選定
- 訓練データを使用したモデルの訓練
評価と最適化
- テストデータを使用したモデルの評価
- パフォーマンスの最適化(例:誤り率の低減)
今後の展望
音声認識技術は進化を続けており、自然言語処理(NLP)や機械学習の進歩により、さらに精度が向上しています。
将来的には、より複雑な言語や方言に対応し、より自然なインタラクションが可能になることが期待されます。
まとめ
Pythonとディープラーニングを使った音声認識は、高度に発展した分野であり、継続的に進化しています。
実装には専門的な知識とリソースが必要ですが、その可能性は計り知れません。
この分野は、AIと人間のインタラクションを変革する可能性を秘めています。
以上、Pythonを用いたディープラーニングで音声認識はできるのかについてでした。
最後までお読みいただき、ありがとうございました。