ディープラーニングを用いた翻訳技術は、近年大きな進歩を遂げています。
この分野は、自然言語処理(Natural Language Processing, NLP)の一環として発展しており、コンピュータが人間の言語を理解し、処理する能力を高めることを目指しています。
以下にディープラーニングを活用した翻訳技術の概要を説明します。
目次
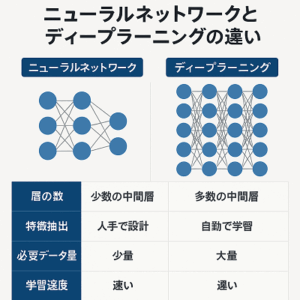
ディープラーニングとは

ディープラーニングは、多層的なニューラルネットワークを用いた機械学習の一種です。
これは、人間の脳の働きを模倣したもので、多数の隠れ層を持つことによって、複雑なパターンやデータの特徴を学習することができます。
ディープラーニングは画像認識、音声認識、そして言語処理の分野で広く用いられています。
ディープラーニングによる翻訳のメカニズム

- 単語埋め込み(Word Embedding): ディープラーニングに基づく翻訳システムでは、まず単語をベクトル形式に変換します。これにより、単語間の意味的な関係を数値化し、コンピュータが理解しやすくします。
- エンコーダ・デコーダモデル: 多くのシステムはエンコーダ・デコーダの枠組みを使用しています。エンコーダは入力言語の文を理解し、その意味を内部表現に変換します。次に、デコーダがこの内部表現を出力言語の文に変換します。
- 注意機構(Attention Mechanism): この機構は、翻訳時にモデルが入力文の重要な部分に「注意」を払うことを可能にします。これにより、文脈に応じたより正確な翻訳が実現します。
- トランスフォーマーモデル: 近年の翻訳技術の進歩において、トランスフォーマーモデルは重要な役割を果たしています。このモデルは、並列処理と注意機構を活用して、効率的かつ高速に翻訳を行います。
ディープラーニングの翻訳のメリット
- 高い精度と流暢さ: ディープラーニングモデルは、大量のデータから学習することで、自然で流暢な翻訳を生成することができます。これにより、人間に近いレベルの翻訳品質が得られます。
- 文脈の理解: ディープラーニングは、単語やフレーズを単独の要素としてではなく、全体の文脈の中で理解することができます。これにより、より正確な翻訳が可能になります。
- 多言語対応の柔軟性: トランスフォーマーのような最新のモデルは、多言語間の翻訳においても高い効率と精度を示します。
- 継続的な学習と改善: ディープラーニングモデルは、新しいデータに基づいて継続的に学習し、時間とともに改善されます。
- 特殊な用語の取り扱い: 専門的な用語やジャルゴンも、適切に訓練されたディープラーニングモデルを使用することで、正確に翻訳することが可能です。
ディープラーニングの翻訳のデメリット
- 大量の訓練データが必要: ディープラーニングモデルは、高い性能を発揮するために大量の訓練データを必要とします。これは、一部の言語や特殊な用途には制限となる場合があります。
- 計算資源の要求: 高度なディープラーニングモデルは、大規模な計算資源を必要とします。これには、高性能のGPUや大量のストレージが含まれます。
- 過信の問題: モデルが生成する翻訳に過度に依存すると、時に誤訳や不自然な表現が見逃されることがあります。
- バイアスの問題: 訓練データに含まれるバイアスがモデルに継承されることがあり、これが翻訳の質に影響を与える可能性があります。
- 透明性の欠如: ディープラーニングモデルは「ブラックボックス」として知られており、その意思決定プロセスが不透明であることが多いです。
- 実時間翻訳の課題: 高度なモデルでは、リアルタイムでの翻訳が遅延することがあります。
ディープラーニングによる翻訳技術は、国際コミュニケーションの障壁を低減し、異なる言語や文化間の相互理解を深める重要なツールとなっています。
今後も技術の発展に伴い、さらに高度な翻訳が実現されることが期待されています。
以上、ディープラーニングの翻訳についてでした。
最後までお読みいただき、ありがとうございました。