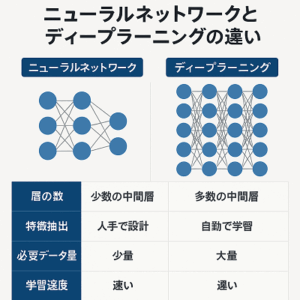
ディープラーニングは機械学習の一分野であり、データから複雑なパターンを学習するために深層ニューラルネットワークを使用します。
ディープラーニングの手法は多岐にわたり、それぞれ異なるタイプの問題やデータに適しています。
ここでは、主要なディープラーニングの種類を詳しく説明します。
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワーク(CNN)は、特に画像認識やビデオ分析において優れた性能を発揮するディープラーニングの一種です。
CNNは、複数の畳み込み層、プーリング層、そして通常の完全連結層(fully connected layers)を含んで構成されています。
それぞれの層は特定の役割を担い、画像から特徴を効果的に抽出するために重要です。
応用分野
- 画像分類: 写真に映る物体を識別する。
- 物体検出: 画像内の特定の物体の位置と種類を特定する。
- 顔認識: 人の顔を識別し、識別する。
- 自動運転車: 道路上の障害物、信号、標識などを認識する。
- 医療画像分析: MRIやCTスキャンの分析に使用されます。
再帰型ニューラルネットワーク(RNN)
再帰型ニューラルネットワーク(RNN)は、特に時系列データや自然言語処理(NLP)の分野で有効なディープラーニングのモデルです。
RNNの重要な特徴は、過去の情報を記憶して現在の入力と組み合わせて処理する能力にあります。
これにより、時間的な連続性や文脈的な情報を含むデータに対して優れた性能を発揮します。
応用分野
- 自然言語処理(NLP): 言語モデルの構築、テキスト生成、機械翻訳、感情分析など。
- 時系列データ解析: 株価予測、気象予測、シーケンスデータのパターン認識など。
- 音声認識: 音声からテキストへの変換、音声ベースのインタラクティブシステム。
長短期記憶ネットワーク(LSTM)

長短期記憶ネットワーク(Long Short-Term Memory, LSTM)は、再帰型ニューラルネットワーク(RNN)の一種で、特に長期的な依存関係を扱う際に優れた性能を発揮します。
標準的なRNNが抱える勾配消失問題を克服するために設計されたLSTMは、自然言語処理(NLP)、音声認識、時系列データ解析などの分野で広く利用されています。
応用分野
- 自然言語処理: 機械翻訳、テキスト生成、感情分析など。
- 音声認識: 音声をテキストに変換するシステム。
- 時系列予測: 株価予測、気象予測、医療データ分析など。
- ビデオ処理: ビデオフレーム間の時間的な関係を理解するために使用されます。
オートエンコーダー
オートエンコーダーは、データの効率的な圧縮表現(エンコーディング)を学習するためのニューラルネットワークの一種です。
主に教師なし学習の枠組みで使用され、入力データを低次元の表現に変換し(エンコーディング)、その後、この低次元表現から元のデータを再構築する(デコーディング)ことを目的としています。
この過程で、オートエンコーダーはデータの重要な特徴を捉えることができます。
応用分野
- データ圧縮: データの低次元表現を学習することにより、効率的なデータ圧縮が可能になります。
- ノイズ除去: デノイジングオートエンコーダーは、画像や音声データからノイズを除去するのに使用されます。
- 特徴抽出: オートエンコーダーは、データから有用な特徴を自動で抽出するのに利用されます。
- 異常検出: 正常なデータのみを使用してオートエンコーダーを訓練すると、異常なデータを識別するのに使用できます。
敵対的生成ネットワーク(GAN)
敵対的生成ネットワーク(Generative Adversarial Networks, GANs)は、ディープラーニングにおける一種のアーキテクチャで、特に新しいデータの生成に関して注目されています。
GANは、2つのニューラルネットワーク、すなわち生成器(Generator)と識別器(Discriminator)を競争させることによって機能します。
この競争的な学習プロセスを通じて、GANは非常にリアルな画像、音声、テキストなどを生成する能力を持つようになります。
応用分野
- 画像生成: 芸術作品、ファッションデザイン、顔画像など、リアルな画像の生成。
- 画像スタイル変換: ある画像のスタイルを別の画像に適用する(例:写真を絵画風に変換)。
- データ拡張: 学習データが不足している場合に、新しいデータを生成してデータセットを拡充。
- 超解像度: 低解像度の画像を高解像度に変換。
- テキストから画像へ: 自然言語の記述から対応する画像を生成。
トランスフォーマー

トランスフォーマー(Transformer)モデルは、特に自然言語処理(NLP)領域において革命をもたらしたディープラーニングのアーキテクチャです。
2017年にGoogleの研究者によって提案されたこのモデルは、従来のRNNやLSTMに依存することなく、大量のテキストデータから複雑な言語パターンを学習する能力を持っています。
応用分野
- 機械翻訳: Google翻訳などのサービスで使用されています。
- テキスト生成: 高品質なテキストコンテンツの生成。
- 感情分析: テキストの感情トーンを理解する。
- 要約: 長い文書を短い要約に変換する。
- 質問応答システム: 自然言語の質問に対する回答を生成する。
これらのディープラーニングの手法は、それぞれ特有の特徴と応用範囲を持ちます。
最適な手法の選択は、解決しようとする問題の性質、利用可能なデータの種類、求められる性能によって異なります。
また、これらの手法は組み合わせて使用することも可能で、より複雑な問題を解決するための強力なツールとなっています。
以上、ディープラーニングの種類についてでした。
最後までお読みいただき、ありがとうございました。