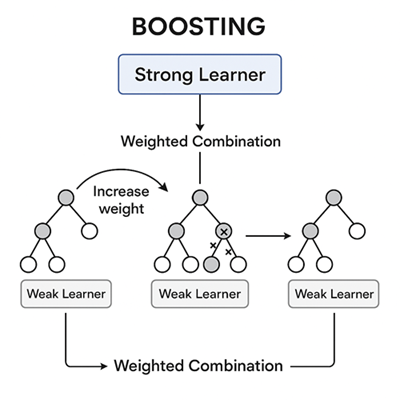

機械学習におけるブースティングとは、複数の弱い学習器(Weak Learners)を順番に学習させ、それらを組み合わせて強力なモデル(Strong Learner)を構築する手法のことです。
アンサンブル学習の一種であり、特に分類や回帰タスクで高い精度を発揮します。
基本概念
ブースティングの根本的なアイデアは、
「前のモデルが間違えた部分を、次のモデルが重点的に学習して補う」
というものです。
学習の流れは次の通りです。
- 初期モデルを訓練して予測する。
- 誤分類・誤差の大きいデータに重みを加える。
- 次のモデルが、その難しいデータを中心に学習する。
- これを繰り返し、最終的に複数のモデルを重み付きで統合して最終予測を得る。
単体では精度の低い弱学習器でも、多数組み合わせることで強力な予測性能を発揮するのがブースティングの特徴です。
弱学習器(Weak Learner)とは?
「弱学習器」とは、単純で、わずかにランダムよりも良い予測を行うモデルを指します。
理論的には「ランダムより少し良い」が条件ですが、実務では「複雑すぎない単純なモデル」という程度の意味合いで使われます。
ブースティングでは、弱学習器として主に深さ1〜3程度の決定木が使われます。
代表的なブースティング手法
AdaBoost(Adaptive Boosting)
ブースティングの原型的な手法。
各データに重みを割り当て、誤分類されたサンプルの重みを増やすことで、次のモデルがそれらを重視して学習します。
最終予測は、すべてのモデルの出力に (\alpha_t) を掛け合わせた重み付き多数決で求めます。
シンプルで直感的ですが、外れ値やノイズに敏感という弱点があります。
Gradient Boosting(勾配ブースティング)
AdaBoostを一般化した手法で、損失関数の勾配方向(誤差を減らす方向)に新たなモデルを追加していくアルゴリズムです。
誤差を直接扱うのではなく、損失関数の負の勾配(擬似残差)を学習します。
- 最初のモデルを作成し、損失を計算。
- 損失の勾配(残差)を予測する新しい木を訓練。
- 前モデルに「一歩だけ」加算して改善。
これを繰り返すことで損失を最小化していきます。
多様な損失関数を扱え、分類・回帰どちらにも対応可能です。
XGBoost(Extreme Gradient Boosting)
Gradient Boosting を改良した高速・高精度な実装です。
主な特徴は次の通りです。
- 二次近似(勾配+ヘッセ行列)を用いて学習を安定化。
- L1/L2正則化による過学習の抑制。
- 並列処理とメモリ最適化による高速化。
データ分析コンペ(Kaggleなど)で圧倒的な人気を誇る理由は、精度と効率のバランスにあります。
LightGBM(Light Gradient Boosting Machine)
Microsoftが開発した勾配ブースティングの高速実装。
主な特徴
- Histogramベースの近似分割で高速化。
- Leaf-wise(葉優先)成長により精度を高める。
- GOSS / EFB による大規模データ最適化。
- カテゴリ変数・欠損値の自動処理対応。
大規模・高次元データで特に高いパフォーマンスを発揮しますが、小規模データでは過学習しやすい点に注意が必要です。
CatBoost(Categorical Boosting)
Yandexが開発した、カテゴリ変数を得意とするブースティング手法です。
主な特徴
- ターゲットエンコーディングを順序統計で処理し、データリークを防止。
- Ordered Boosting により過学習を抑制。
- 数値・カテゴリ混在データでも安定した精度を発揮。
ブースティングとバギングの違い
| 比較項目 | ブースティング | バギング(例:ランダムフォレスト) |
|---|---|---|
| 学習の仕組み | 逐次的(前の誤りを補う) | 並列的(独立に学習) |
| データの扱い | 重みを付与(誤り重視) | サンプリング(ブートストラップ) |
| 主な目的 | バイアス低減(精度の向上) | バリアンス低減(安定性向上) |
| モデル間の依存性 | 高い(前モデルに依存) | 低い(独立学習) |
ブースティングは「誤りを補って精度を上げる」ことに長け、バギングは「分散を減らして安定性を高める」ことに強い、という棲み分けです。
ブースティングのメリットと課題
メリット
- 単純なモデルを組み合わせて高精度なモデルを構築できる。
- 非線形な関係性を捉えるのが得意。
- 多様な損失関数に対応し、柔軟な適用が可能。
デメリット
- ノイズや外れ値に敏感(特にAdaBoost)。
- 学習コスト・パラメータチューニングが重い。
- 過学習のリスク(LightGBMなどではLeaf-wise成長が深くなりすぎる場合も)。
チューニングの要点
ブースティング系モデルの性能は、ハイパーパラメータ調整で大きく変わります。
重要なポイントは次の通りです。
| パラメータ | 役割 | 調整のポイント |
|---|---|---|
| 学習率(learning_rate) | 更新の一歩の大きさ | 小さくすると安定するが木数が必要 |
| 木の深さ(max_depth) | モデルの複雑さ | 深すぎると過学習、浅すぎると未学習 |
| 木の数(n_estimators) | 学習回数 | 学習率とのトレードオフ |
| 早期終了(early_stopping) | 過学習防止 | バリデーション損失の監視に有効 |
まとめ
ブースティングは、
「弱い学習器を逐次的に積み上げ、誤りを補正しながら強力なモデルを構築する」という考え方に基づくアンサンブル手法です。
代表的な実装である XGBoost, LightGBM, CatBoost は、いずれも勾配ブースティングを発展させたものであり、現代の機械学習における最も強力かつ実用的なアルゴリズム群の一つです。
以上、機械学習におけるブースティングについてでした。
最後までお読みいただき、ありがとうございました。







