
ディープラーニングにおける教師なし学習(Unsupervised Learning)は、ラベル付けされていないデータを使用してモデルがパターンや構造を発見する学習方法です。
この種の学習では、入力データに明確な「正解」が与えられず、モデルはデータ内の隠れた特徴や関係性を自ら見つけ出します。
目次
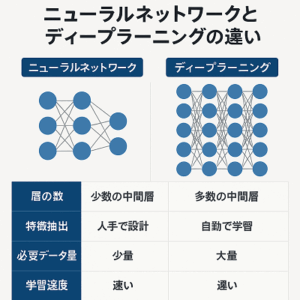
教師なし学習の特徴
- ラベルの不要性
- 教師なし学習では、ラベルやターゲット変数が必要ありません。データ自体のみを使用してパターンを探します。
- データの構造発見
- データ内に存在する隠れた構造や関係性を識別します。これは、データがどのように組織されているか、またはデータポイント間の関係性を理解するのに役立ちます。
- 探索的データ分析
- 教師なし学習は、新しい洞察や未知のパターンを発見するための探索的手法として使用されることが多いです。
- 複雑なデータ処理
- 高次元データや複雑なデータ構造を扱う際に有効です。これにより、データの簡略化やより扱いやすい形式への変換が可能になります。
主なアプローチ
- クラスタリング(Clustering)
- 類似の特徴を持つデータポイントをグループ化します。例: K-平均法、階層型クラスタリング。
- 次元削減(Dimensionality Reduction)
- データの次元数を減少させることで、データの扱いやすさを向上させ、視覚化を容易にします。例: 主成分分析(PCA)、t-SNE。
- 異常検出(Anomaly Detection)
- 正常なデータパターンから逸脱する異常値や外れ値を識別します。
- 関連規則学習(Association Rule Learning)
- 大量のデータからアイテム間の関連性やルールを発見します。例: マーケットバスケット分析。
ディープラーニングにおける教師なし学習の応用

オートエンコーダ
- 特徴抽出と次元削減: オートエンコーダは、入力データをより低次元の表現に圧縮し、その後元のデータに再構成することで、データの重要な特徴を学習します。
- デノイジング: ノイズのあるデータからノイズを除去し、データのクリーンな表現を生成します。
生成的敵対ネットワーク
- 画像生成: GANはリアルな画像を生成することができます。この技術はアート、ゲームのキャラクターデザイン、リアルタイム映像の生成などに応用されています。
- データ拡張: 限られた量のトレーニングデータを拡張するために、GANを使って新しいデータサンプルを生成します。
異常検出
- 異常パターンの識別: ディープラーニングモデルを用いて、データの中で異常または外れ値となるサンプルを特定します。これは、フラウド検出、ネットワークセキュリティ、医療画像分析などで有用です。
教師なし学習の課題と限界
- 解釈性の難しさ: 教師なし学習で見つかったパターンの意味や重要性を解釈することは困難な場合があります。
- パラメータの調整: クラスタリングや次元削減の方法によっては、最適なパラメータの設定が重要になりますが、これはしばしば試行錯誤が必要です。
まとめ
教師なし学習は、特にラベル付けされていない大量のデータに対して洞察を得たい場合や、データ内の未知のパターンを探索する場合に非常に有効です。
ディープラーニングにおける教師なし学習の進化は、より複雑で高度なデータ分析を可能にし、新しい形のAIアプリケーションを創出しています。
以上、ディープラーニングの教師なし学習についてでした。
最後までお読みいただき、ありがとうございました。