
ディープラーニングを使用した音声認識についての詳細な説明を行います。
音声認識は、人間の声をテキストに変換する技術であり、ディープラーニングはその精度を飛躍的に向上させる重要な役割を果たしています。
目次
ディープラーニングとは何か
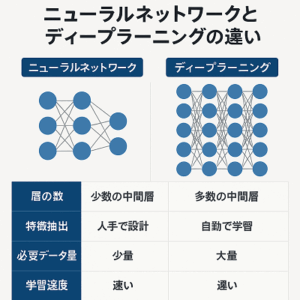
ディープラーニングは、人工知能(AI)の一分野であり、人間の脳のニューラルネットワークを模倣したアルゴリズムを使用します。
これらのアルゴリズムは、大量のデータを通じて学習し、特定のタスクを実行する能力を向上させます。
ディープラーニングは、多層のニューラルネットワーク(深層ニューラルネットワーク)を使用しており、複雑なパターンやデータの関連性を抽出できます。
音声認識とディープラーニング
音声認識は、人間の話す言葉をコンピュータが理解し、テキストに変換する技術です。
ディープラーニングを音声認識に応用することで、様々なアクセント、方言、話し方に対応し、より正確な認識が可能になっています。
音声認識の基本的なプロセス
音声データの収集
- データの取得: 音声認識のためのデータは、通常、マイクロフォンを通じて録音された音声から取得されます。この音声データは、様々な環境音や話者の声色を含んでいます。
音声信号の前処理
- ノイズ除去: 音声データから不要なノイズを取り除きます。このプロセスは、背景の騒音やエコーなどの影響を最小限に抑えるために重要です。
- 信号の正規化: 音声の音量を均一化し、データの一貫性を保ちます。
特徴抽出
- 特徴量の抽出: 音声からメル周波数ケプストラム係数(MFCC)やスペクトログラムなどの特徴量を抽出します。これらの特徴量は、音声の周波数や持続時間などを表します。
- 特徴の正規化: 抽出された特徴量をスケーリングして、モデルが学習しやすい形式にします。
ディープラーニングモデルの適用
- モデルの構築: 音声認識には、畳み込みニューラルネットワーク(CNN)、リカレントニューラルネットワーク(RNN)、またはその組み合わせが使用されます。最近では、トランスフォーマーモデルも使用され始めています。
- モデルの学習: ディープラーニングモデルは、大量のラベル付き音声データを使用して訓練されます。モデルは、音声の特徴から単語や文を予測する方法を学びます。
音声認識の実行
- 音声からテキストへの変換: 訓練されたモデルは、新しい音声データを入力として受け取り、それをテキストに変換します。この過程では、モデルは音声の特徴から、話されている言葉を認識し、適切なテキストを生成します。
後処理と最適化
- エラー訂正: 認識されたテキストは、文法的な正確さや一貫性を確保するためにさらに処理されることがあります。
- モデルの最適化: 継続的な学習と評価を通じて、モデルの性能を向上させます。
応用分野

- スマートアシスタント: SiriやGoogleアシスタントなど、ユーザーの声に応じた情報提供や操作を実現しています。
- 音声翻訳: 異なる言語間でのリアルタイム音声翻訳に応用されています。
- 健康ケア: 患者の声の変化を分析し、病気の早期発見に貢献する可能性があります。
- セキュリティ: 音声による本人認証システムにも利用されています。
今後の展望
- 少量データでの学習: データ収集の困難さを克服し、効率的な学習手法の開発が進んでいます。
- 感情認識: 音声から感情を読み取る研究が進展しており、より洗練された対話システムの構築が期待されています。
ディープラーニングによる音声認識技術は、日々進化しており、私たちの生活にさらに深く組み込まれていくことが予想されます。
この分野の技術革新は、コミュニケーションの方法を根本から変え、新しいビジネスチャンスを生み出す可能性を秘めています。
以上、ディープラーニングの音声認識についてでした。
最後までお読みいただき、ありがとうございました。