カスケード分類器とディープラーニングは、画像処理やオブジェクト検出の分野で使用される二つの異なる技術です。
それぞれの特徴や違いを理解することで、どのような状況で各技術が適しているかを判断するのに役立ちます。
目次
カスケード分類器

カスケード分類器は、オブジェクト検出タスク(特に顔検出)でよく使用されるコンピュータビジョンの手法です。
このアルゴリズムは、複数の「ステージ」または「レベル」からなるカスケード構造を持ち、各ステージで画像の一部を評価してオブジェクトの存在を判断します。
以下にカスケード分類器の主要な特徴と動作の原理を詳しく説明します。
基本原理
- ハール特徴: カスケード分類器は、しばしばハール特徴に基づいています。ハール特徴は、画像の特定領域における明暗の差分を利用したもので、シンプルな長方形の特徴を使用して高速に計算できます。
- AdaBoostアルゴリズム: カスケード分類器はAdaBoost(適応ブースティング)アルゴリズムを使用して、分類器の学習を行います。この過程で、より重要な特徴が重視され、重要でない特徴は無視されるようになります。
- カスケード構造: 分類器は、複数のステージを重ねたカスケード構造を持ちます。初期のステージでは簡単な特徴を用いて高速に判断し、後続のステージでより複雑な特徴を用いて精度を高めます。
メリット
- 高速性: カスケード分類器の最大の利点は、その処理速度です。単純な特徴と効率的なステージベースのアプローチにより、リアルタイムでの顔検出などのタスクが可能になります。
- リソース効率: 限られた計算リソースを持つ環境(例えば、モバイルデバイスや組み込みシステム)での使用に適しています。
- 実装の容易さ: OpenCVなどのライブラリでは、カスケード分類器が簡単に利用できるようになっています。これにより、開発者は容易にオブジェクト検出機能をアプリケーションに組み込むことができます。
- 訓練データへの依存度が比較的低い: 複雑なディープラーニングモデルに比べて、カスケード分類器は比較的少ない訓練データで有効な結果を出すことができます。
デメリット
- 精度の限界: カスケード分類器は、一般的にディープラーニングベースの手法よりも精度が劣ります。特に多様な背景や照明条件下では、誤検出や見逃しが多くなる傾向があります。
- 柔軟性の欠如: 主に顔検出のような特定のタスクに最適化されており、異なる種類のオブジェクト検出にはそのままでは適用できない場合があります。
- 背景やポーズの変化に敏感: カスケード分類器は、トレーニングデータに含まれない背景やオブジェクトのポーズに敏感であり、これがパフォーマンスに大きく影響します。
- データバイアスの問題: トレーニングデータの多様性が不足している場合、カスケード分類器は特定の人種や性別に対して偏った挙動を示すことがあります。
応用分野
- カスケード分類器は、顔検出、特にリアルタイムアプリケーション(例えば、セキュリティカメラやインタラクティブなメディア)に広く使用されています。
- その高速性から、モバイルデバイスや組み込みシステムでの使用に適しています。
ディープラーニング

ディープラーニングは、機械学習の一分野であり、人工知能(AI)の重要な要素です。
この技術は、人間の脳が情報を処理する方法を模倣したディープニューラルネットワークに基づいています。
ディープラーニングは、複雑なデータセットからパターンや特徴を抽出し、分類、予測、判断を行う能力を持ちます。
以下にディープラーニングの重要な側面について詳しく説明します。
基本原理
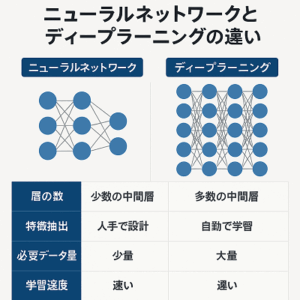
- ニューラルネットワーク: ディープラーニングの基盤は、層状の構造を持つ人工ニューラルネットワークです。各層は多数のニューロン(ノード)で構成され、これらのニューロンは互いに接続されています。
- 学習プロセス: ネットワークは、入力データを受け取り、重み付けされた接続を通じて情報を伝達し、最終的に出力を生成します。学習中、ネットワークはエラーを最小限に抑えるようにこれらの重みを調整します。
- 深層学習: 「深層」という用語は、ニューラルネットワークが複数の隠れ層を持つことを指します。これにより、ネットワークはより複雑で抽象的な特徴を学習することができます。
メリット
- 高い学習能力: ディープラーニングモデルは、非常に複雑なデータパターンを学習する能力があります。これにより、画像認識、言語理解、ゲームプレイなどの複雑なタスクで人間を超える性能を発揮することができます。
- 多様な応用: ディープラーニングは、さまざまなタイプのデータ(画像、テキスト、音声など)に適用可能で、幅広い分野で利用されています。
- 自動特徴抽出: 従来の機械学習モデルとは異なり、ディープラーニングは人間の介入なしにデータから重要な特徴を自動的に抽出することができます。
- 改善し続ける性能: 大量のデータと強力なコンピューティングリソースを使えば使うほど、ディープラーニングモデルは学習し続け、その精度を向上させることができます。
デメリット
- 大量のデータが必要: 効果的に機能するためには、大量のラベル付きトレーニングデータが必要です。これは、データ収集と前処理に多大な時間とリソースを要する場合があります。
- 計算コストが高い: ディープラーニングは計算リソースを大量に消費します。特に、大規模なモデルのトレーニングには高性能なGPUやTPUが必要であり、これはコストが高くなる可能性があります。
- 解釈性の欠如: ディープラーニングモデルは「ブラックボックス」と見なされることが多く、その決定や予測の理由を理解することが難しい場合があります。
- 過学習のリスク: モデルがトレーニングデータに過度に適応してしまい、新しいデータに対してうまく一般化できないことがあります。
- 倫理的、社会的問題: バイアスのあるデータでトレーニングされたモデルは、偏見を持った結果を生み出すことがあります。これは、特に人種、性別、年齢などに関連するタスクで顕著です。
応用分野
- 画像認識: 顔認識、物体検出など。
- 自然言語処理: 機械翻訳、チャットボット、テキスト生成など。
- 音声認識: 音声アシスタント、音声コマンド処理など。
- 推薦システム: オンラインショッピング、動画配信サービスでの個人化された推薦など。
まとめ
- カスケード分類器は単純で高速ですが、複雑なタスクや多様なデータセットには不向きです。一方で、ディープラーニングは高精度で柔軟性がありますが、計算リソースとデータ量の点で要求が高いです。
- どちらの技術を選択するかは、タスクの複雑さ、利用可能なリソース、精度の要求度などによって異なります。
以上、カスケード分類器とディープラーニングの違いについてでした。
最後までお読みいただき、ありがとうございました。