ディープラーニングを用いた音声合成は、人間の声を模倣し、テキストから音声を生成する技術です。
この分野は近年、特にディープラーニングの進化により大きく発展しています。
以下にディープラーニングに基づく音声合成の主要な側面について詳しく説明します。
目次
ディープラーニングと音声合成

- 基本原理: ディープラーニングに基づく音声合成は、通常、大量の音声データを使用してニューラルネットワークを訓練します。この訓練により、テキスト入力から音声出力への変換が可能になります。
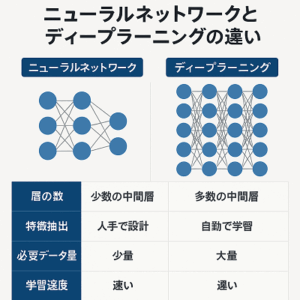
- アーキテクチャ: 一般的なアーキテクチャには、畳み込みニューラルネットワーク(CNN)、再帰型ニューラルネットワーク(RNN)、特に長・短期記憶(LSTM)ネットワーク、そして最近ではトランスフォーマーモデルがあります。これらは、異なる方式で音声の特徴を学習します。
- モデルの種類:
- WaveNet: GoogleのDeepMindが開発したモデルで、生の音声波形を直接生成します。非常に自然な音声を生成することで知られています。
- Tacotron: エンドツーエンドの音声合成モデルで、テキストからスペクトログラムを生成し、それを音声に変換します。
- Transformer TTS: トランスフォーマーに基づくモデルで、効率的な学習と高品質な音声生成を実現します。
- 特徴と応用:
- 感情表現: ディープラーニングによる音声合成では、感情を含めることが可能です。これにより、音声はよりリアルで人間らしいものになります。
- 多言語対応: 異なる言語やアクセントに対応するモデルが開発されています。
- カスタマイズ: 特定の声や話し方を模倣するためのカスタマイズが可能です。
技術的課題
データの取得と品質
- 大量の訓練データ: 高品質な音声合成モデルを訓練するには、大量のラベル付き音声データが必要です。このデータ収集は、時間とコストがかかります。
- データの多様性: さまざまな言語、アクセント、話し方をカバーするためには、多様なデータが必要です。特定の言語やアクセントに偏ったデータセットは、合成音声の品質に影響を与えます。
感情とインフォレーションの表現
- 感情の表現: 人間の声には感情が込められていますが、これを機械で再現することは非常に困難です。感情のニュアンスを正確に捉え、表現することは大きな課題です。
- 発話のインフォレーション: 言葉の強調やイントネーションも重要です。これらを自然に再現することは、特に難しいです。
リアルタイム性と効率
- リアルタイム処理: 高品質な音声合成をリアルタイムで行うには、大きな計算能力が必要です。これは特にモバイルデバイスや組み込みシステムでの応用を難しくしています。
- 計算資源の最適化: 効率的なアルゴリズムの開発は、計算資源の制限を考慮した上で重要です。
最近の進展と未来

- リアルタイム性の向上: ハードウェアの進化とアルゴリズムの最適化により、リアルタイムでの音声合成が可能になりつつあります。
- 自然性の向上: 継続的な研究により、音声の自然さが向上しています。
- 応用分野の拡大: 音声アシスタント、オーディオブック、自動音声応答(IVR)システムなど、さまざまな分野での応用が拡大しています。
ディープラーニングによる音声合成技術は、その自然な音声生成能力により、人間と機械のインタラクションに革命をもたらす可能性を秘めています。
この技術の進化は、今後も大きな注目を集めるでしょう。
以上、ディープラーニングの音声合成についてでした。
最後までお読みいただき、ありがとうございました。