ディープラーニングにおける「超解像(Super Resolution, SR)」技術は、低解像度の画像や動画を高解像度に変換する一種の画像処理技術です。
この技術は特に、解像度の低い画像を詳細で高品質な画像に変換するのに用いられます。
以下にディープラーニングを利用した超解像技術の主要な概念と特徴を説明します。
目次
超解像の基本概念

- 解像度の向上: 超解像は、画像の解像度を物理的に向上させることを目指します。これにより、画像のピクセル数が増加し、より細かいディテールが表現されます。
- 画像の品質改善: 単にピクセル数を増やすだけでなく、画像の品質を向上させることも目的です。これには、鮮明さの向上、ノイズの除去、エッジの強化などが含まれます。
- 情報の補完: 低解像度の画像には、高解像度画像に含まれる情報の多くが欠けています。超解像技術は、欠けている情報を補完し、よりリアルで詳細な画像を生成します。
ディープラーニングによる超解像
ディープラーニングによる超解像の基本
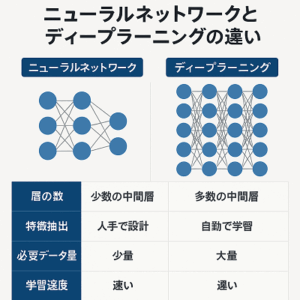
- ニューラルネットワーク: この技術は、主に畳み込みニューラルネットワーク(Convolutional Neural Networks, CNN)を使用します。CNNは、画像の特徴を抽出し、それらを利用して高解像度画像を生成するのに適しています。
- 学習プロセス: ディープラーニングモデルは、低解像度と高解像度の画像ペアを使用して訓練されます。このプロセスを通じて、モデルは低解像度の画像から高解像度の画像を生成する方法を学習します。
- 損失関数: 超解像で用いられる損失関数は、生成された画像の品質を評価します。これには、ピクセルレベルの誤差(例:平均二乗誤差)や、知覚的品質を考慮した誤差(例:Perceptual Loss)があります。
代表的なディープラーニング超解像モデル
- SRCNN(Super-Resolution Convolutional Neural Network): 超解像技術における先駆的なディープラーニングモデルの一つ。低解像度画像を入力として、高解像度画像を出力します。
- ESRGAN(Enhanced Super-Resolution Generative Adversarial Networks): GAN(Generative Adversarial Network)をベースにしたモデルで、よりリアルで高品質な画像を生成します。
- VDSR(Very Deep Super Resolution): より深いネットワーク構造を採用し、高い精度の超解像を実現します。
応用分野

- 医療画像処理: MRIやCTスキャンなどの画像の解像度を向上させ、より正確な診断を支援します。
- 衛星画像: 地球観測や環境モニタリングで使用される衛星画像の品質を向上させます。
- 監視カメラ: 安全監視や犯罪防止のためのカメラの映像の詳細を強化します。
- エンターテイメント: 古い映画やビデオの画質を向上させ、新しい視聴体験を提供します。
超解像の課題と展望
- 計算コスト: 高度なディープラーニングモデルは計算資源を大量に消費します。リアルタイム処理には高性能なハードウェアが必要になることがあります。
- トレーニングデータ: 高品質な超解像結果を得るためには、大量かつ多様なトレーニングデータが必要です。
- 汎用性の問題: 特定の種類の画像に特化して訓練されたモデルは、他の種類の画像に対しては効果が低い可能性があります。
今後の研究と開発により、超解像技術はさらに進化し、より多様な応用分野での利用が期待されています。
また、AI技術の進歩に伴い、より効率的で実用的な超解像技術の開発が進んでいくことでしょう。
以上、ディープラーニングの超解像についてでした。
最後までお読みいただき、ありがとうございました。