ディープラーニングの実装についての詳細な説明を行います。
ディープラーニングは、機械学習の一分野であり、特に多層ニューラルネットワークの訓練に関連しています。
ここでは、基本的なコンセプト、ネットワークの構築、トレーニング方法、そして実装上の一般的な課題について説明します。
目次
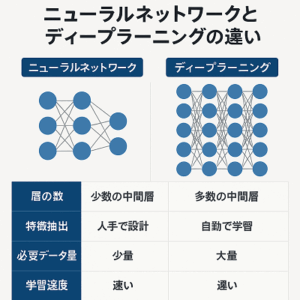
ディープラーニングの特徴
- 表現学習(Representation Learning): ディープラーニングは、データから自動的に特徴を学習し、これを用いてタスクを実行します。これにより、手動で特徴を設計する必要がなくなります。
- 深さの重要性: ディープラーニングでは、多数の隠れ層を使用することで、より複雑で抽象的な特徴表現を学習することができます。
- 大規模データと計算能力: 効果的なディープラーニングモデルの訓練には、大量のデータと高い計算能力(例えば、GPU)が必要です。
- 適用分野: ディープラーニングは、画像認識、自然言語処理、音声認識、ゲームプレイなど、多岐にわたる分野で応用されています。
基本的なコンセプト

- ニューラルネットワーク: ディープラーニングの基礎となるのは、人間の脳を模倣したニューラルネットワークです。これは、入力層、一つ以上の隠れ層、そして出力層から構成されます。
- ニューロン: これらの層はニューロン(またはノード)で構成されており、各ニューロンは入力を受け取り、活性化関数を通して出力を行います。
- 活性化関数: 活性化関数は、ニューロンの出力を決定します。例えば、ReLU(Rectified Linear Unit)やシグモイド関数がよく使用されます。
- 重みとバイアス: ニューラルネットワークの学習は、入力データに基づいて適切な重みとバイアスを調整することによって行われます。
ネットワークの構築
- アーキテクチャの選択: ネットワークのアーキテクチャ(層の数、各層のニューロンの数、活性化関数の種類など)を決定します。
- データの前処理: データをネットワークに適した形式に変換します。例えば、画像データの場合は正規化を行い、ピクセル値を0から1の範囲にスケーリングすることが一般的です。
- モデルの定義: 使用するフレームワーク(例:TensorFlow、PyTorch)でモデルを定義します。
学習プロセス
- 順伝播(Forward Propagation): 入力データは入力層からネットワークを通して順に伝播し、最終的に出力層で予測値が生成されます。
- 損失関数(Loss Function): 予測値と実際の値との差異を計算するために損失関数が用いられます。例えば、回帰問題では平均二乗誤差、分類問題ではクロスエントロピー損失が一般的です。
- 逆伝播(Backpropagation): 損失関数の勾配を計算し、これを用いてネットワークの重みとバイアスを更新します。このプロセスは、損失を最小限に抑えるようにネットワークを最適化します。
- 最適化アルゴリズム(Optimization Algorithms): 重みの更新には、確率的勾配降下法(SGD)、Adam、RMSpropなどの最適化アルゴリズムが使用されます。
実装上の課題
- 過学習: モデルがトレーニングデータに過剰に適合してしまうこと。これを防ぐためには、ドロップアウト、正則化、データ拡張などの手法が用いられます。
- ハイパーパラメータの調整: ネットワークのアーキテクチャやトレーニングプロセスのハイパーパラメータ(学習率、バッチサイズなど)の調整は、性能に大きな影響を与えます。
- 計算資源: ディープラーニングは計算集約型であり、特に大きなモデルや大量のデータを扱う場合は、GPUやTPUなどの専用ハードウェアが必要になることがあります。
ディープラーニングの実装は、これらの要素を考慮しながら行う必要があり、成功するためには、理論の理解だけでなく、実践的な経験も非常に重要です。
さまざまな問題に対してモデルを試し、結果を分析し、調整を繰り返すことが、効果的なディープラーニングモデルを構築する鍵となります。
以上、ディープラーニングの実装についてでした。
最後までお読みいただき、ありがとうございました。