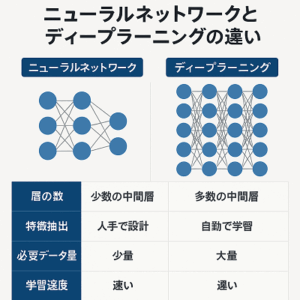
ディープラーニングの事前学習済みモデルは、特定のタスクに対して大規模なデータセットで訓練されたモデルであり、後に特定の用途やより狭いデータセットに対して微調整(ファインチューニング)することができます。
これらのモデルは、多くの場合、計算資源が限られた環境や特定の専門知識がない状況でも、高度なタスクを実行するために使われます。
以下にいくつかの代表的な事前学習済みモデルを示します。
目次
画像処理モデル

- VGGNet: 特にVGG16とVGG19が有名で、そのシンプルなアーキテクチャにも関わらず、画像分類や特徴抽出に優れた性能を発揮します。
- ResNet: 残差学習を導入し、非常に深いネットワークでも効率的に学習できるように設計されています。ResNet50, ResNet101などがあります。
- Inception (GoogLeNet): 異なるスケールの特徴を同時に捉えるインセプションモジュールを使用し、効率的な計算と高い精度を実現します。
- YOLO (You Only Look Once): リアルタイム物体検出に適しており、高速かつ効率的です。
- SSD (Single Shot MultiBox Detector): YOLOと同様にリアルタイムの物体検出に利用され、速度と精度のバランスが取れています。
自然言語処理(NLP)モデル

- BERT (Bidirectional Encoder Representations from Transformers): テキストの双方向の文脈を考慮して学習し、感情分析、名前付きエンティティ認識(NER)、質問応答などのタスクに優れた性能を示します。
- GPT (Generative Pretrained Transformer): GPT-2、GPT-3など、自然言語生成に特化しており、文章生成、会話AI、テキスト補完などに利用されます。
- Transformer-XL: 長い文書やシーケンスを扱うのに適しており、文脈をより長く保持できます。
- mBERT (Multilingual BERT): 複数の言語に対応したBERTモデルで、多言語間のNLPタスクに適用できます。
- XLM-RoBERTa: 多言語テキストに適用できる強化されたRoBERTaモデルです。
オーディオ・音声処理モデル
- DeepSpeech: Mozillaによって開発された、音声からテキストへの変換(STT: Speech-to-Text)モデルです。リアルタイムでの音声認識に優れています。
- Wave2Vec 2.0: Facebook AIが開発した、未ラベルのオーディオデータから直接学習するモデルです。
- Tacotron 2: Googleによって開発されたテキストから音声への変換(TTS: Text-to-Speech)モデルで、自然な発話を生成します。
- WaveNet: DeepMindによって開発されたモデルで、高品質な音声合成を実現します。リアルな人間の声に非常に近い音声を生成できます。
その他のモデル
- MobileNet: 軽量でありながら効果的な画像認識と分類が可能で、モバイルデバイスや組み込みシステムでの使用に適しています。
- EfficientNet: 画像認識において、計算効率と精度の良いバランスを実現しています。
これらのモデルは、データの前処理から特徴抽出、分類までの複雑なプロセスを抽象化し、開発者が特定のタスクに集中できるようにします。
事前学習済みモデルを使用することで、大規模なデータセットや高度な計算資源が不足している状況でも、高度なディープラーニングアプリケーションを実現することが可能です。
以上、ディープラーニングの事前学習済みモデルの一覧についてでした。
最後までお読みいただき、ありがとうございました。