
CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)は、主に画像認識分野で高い性能を発揮する深層学習モデルです。
最大の特徴は、画像から有用な特徴を人手で設計することなく、学習を通じて自動的に獲得できる点にあります。
ここでは、CNNの基本構造と各処理の仕組みについて、順を追って解説します。
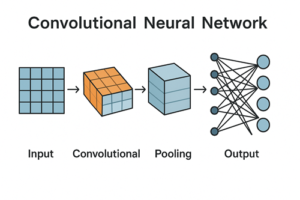
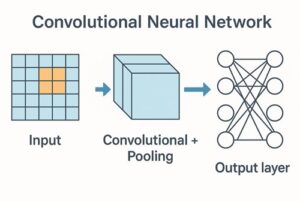
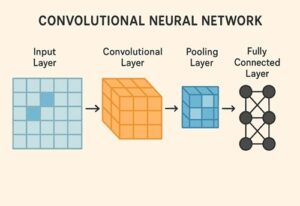
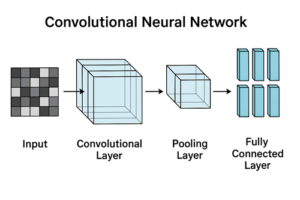
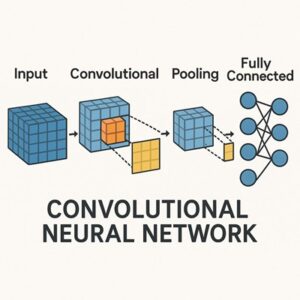
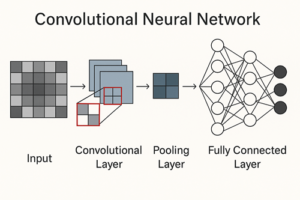
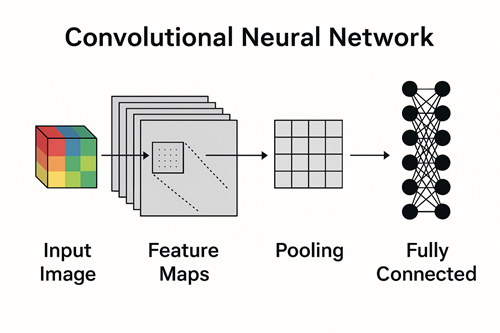
CNNの全体構造
CNNは、大きく分けて次のような層を段階的に重ねた構造を持っています。
- 入力層
- 畳み込み層
- 活性化関数
- プーリング層(またはダウンサンプリング処理)
- 畳み込み系の層を複数回繰り返す
- 全結合層
- 出力層
前半部分では画像の特徴を抽出し、後半部分では抽出された特徴を基に分類や予測を行います。
入力層:画像データの表現
CNNでは、画像を数値の配列(テンソル)として扱います。
- グレースケール画像は「高さ × 幅 × 1」
- RGBカラー画像は「高さ × 幅 × 3」
各要素は画素の明るさや色の強度を表します。
実装上はデータの並び順が異なる場合もありますが、概念としてはこの理解で問題ありません。
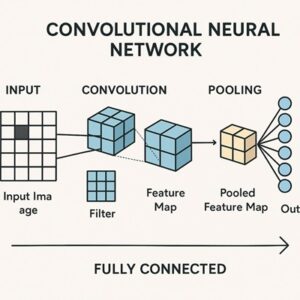
畳み込み層の役割と仕組み
畳み込み処理とは
畳み込み層は、CNNにおいて特徴抽出を担う最も重要な層です。
ここでは「フィルタ(カーネル)」と呼ばれる小さな行列を画像上でスライドさせながら計算を行います。
処理の流れは次の通りです。
- 入力画像の一部分とフィルタの各要素を掛け合わせる
- それらを合計し、必要に応じてバイアス項を加える
- 得られた値を出力として記録する
この処理を画像全体に対して繰り返すことで、局所的な特徴を捉えた出力が得られます。
なお、畳み込み処理では以下の要素が結果に影響します。
- フィルタサイズ
- ストライド(スライド幅)
- パディング(画像の周囲を埋める処理)
これらの設定によって、出力の大きさや特徴の捉え方が変化します。
フィルタが学習する特徴
CNNでは、フィルタの値はあらかじめ決められているのではなく、学習によって最適化されます。
- 浅い層では、エッジや単純なパターンに反応するような特徴
- 深い層では、より複雑で抽象的な特徴
が学習される傾向があります。
これは一般的な傾向であり、必ずしも人間が直感的に理解できる特徴になるとは限りませんが、階層的に表現を学習する点がCNNの重要な特性です。
特徴マップ
畳み込み層の出力は「特徴マップ」と呼ばれます。
複数のフィルタを用いることで、1つの入力画像から複数の特徴マップが生成され、画像を多角的に捉えることが可能になります。
活性化関数の役割
畳み込み処理の出力には、活性化関数が適用されます。
代表的なものが ReLU(Rectified Linear Unit)です。
ReLUは、入力が0以下の場合は0を出力し、正の値はそのまま出力します。
これによりモデルに非線形性が加わり、複雑な表現を学習できるようになります。
また、ReLUは計算が比較的単純で、従来の活性化関数に比べて学習が進みやすいという利点があります。
ただし、条件によっては一部のユニットが学習に寄与しなくなる場合もあるため、万能ではありません。
プーリング層とダウンサンプリング
プーリング層の概要
プーリング層は、特徴マップの空間サイズを縮小するために用いられる層です。
代表的な手法に「最大プーリング」があります。
一定の領域内から最大値を取り出すことで、情報の要点を保ちながらデータ量を削減します。
プーリングの効果と注意点
プーリングには以下のような効果があります。
- 計算量の削減
- ノイズに対する耐性の向上
- 小さな位置ズレに対する頑健性の向上
ただし、プーリングは情報を一部捨てる処理でもあるため、近年のCNNではストライド付き畳み込みなど、別の方法でダウンサンプリングを行う設計も一般的です。
全結合層の役割
畳み込み層やプーリング層で抽出された特徴は、最終的に1次元のベクトルに変換され、全結合層に入力されます。
全結合層では、抽出された特徴を総合的に判断し、どのクラスに属するかを判定します。
この部分は、従来のニューラルネットワークと同様の構造です。
近年では、全結合層の代わりにGlobal Average Poolingを用いる設計も多く見られます。
出力層と分類
多クラス分類問題では、出力層にSoftmax関数が用いられることが一般的です。
Softmaxは、各クラスに属する確率を出力し、その合計は1になります。
最も確率が高いクラスが、モデルの予測結果となります。
CNNが画像認識に適している理由
CNNが画像認識に強い理由として、次の点が挙げられます。
- 画像の局所的な特徴に着目できる
- 同じフィルタを全体に適用する重み共有により効率的に学習できる
- 層を重ねることで、段階的に抽象度の高い表現を学習できる
これらの性質により、CNNは画像データを扱うタスクにおいて高い性能を発揮します。
まとめ
CNNは、畳み込み層による特徴抽出と、全結合層または集約処理による分類を組み合わせた深層学習モデルです。
基本構造を理解しておくことで、VGGやResNet、EfficientNetといった発展的なモデルの理解にもつながります。
以上、CNNの構造や仕組みについてでした。
最後までお読みいただき、ありがとうございました