
CNN(畳み込みニューラルネットワーク)の概要
CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)は、画像データを効率よく扱うために設計された深層学習モデルです。
画像は縦×横×色チャネルという空間構造を持つデータですが、CNNはこの構造を保ったまま特徴を抽出できる点に大きな強みがあります。
従来の全結合型ニューラルネットワークでは、画像を1次元ベクトルとして扱う必要があり、
- パラメータ数が非常に多くなる
- 画素の位置関係が失われる
といった問題がありました。
CNNはこれを畳み込み演算と重み共有によって解決します。
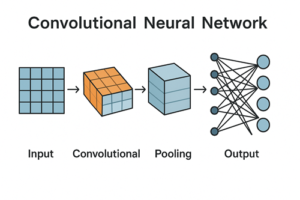
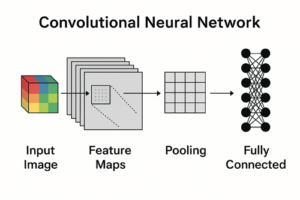
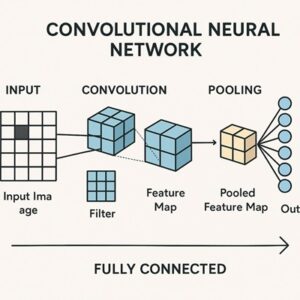
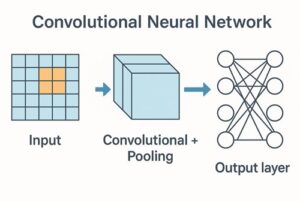
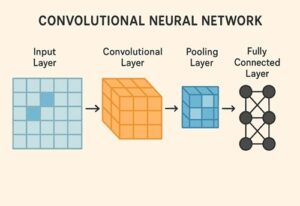
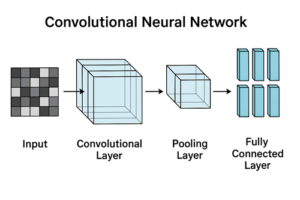
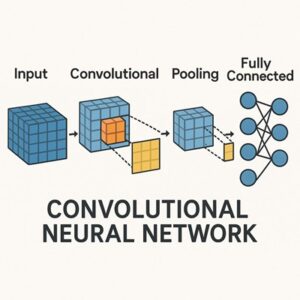
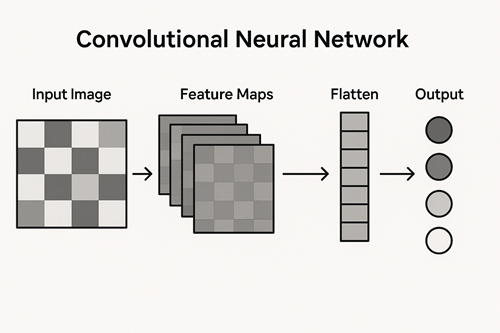
CNNによる画像分類の基本構造
典型的なCNNベースの画像分類モデルは、次のような構成を持ちます。
入力画像
↓
畳み込み層(Convolution Layer)
↓
活性化関数(ReLUなど)
↓
ダウンサンプリング層(Pooling または Strided Convolution)
↓
(上記を複数回繰り返す)
↓
全結合層 または グローバルプーリング
↓
出力層
この構造はモデルによって細部は異なりますが、「特徴抽出部」と「分類部」に分かれるという点は共通しています。
畳み込み層の役割と特徴抽出
畳み込み演算とは何か
畳み込み層では、小さなフィルタ(カーネル)を入力画像上でスライドさせながら計算を行います。
この操作により、画像中の局所的なパターンを検出できます。
CNNは学習の過程で、次のような階層的特徴を自動的に獲得します。
- 浅い層:エッジ、色の変化、単純な線
- 中間層:模様、角、部品的な形状
- 深い層:物体の構成要素や意味的特徴
この「抽象度が徐々に上がる構造」が、CNNによる画像理解の中核です。
重み共有と平行移動への性質
畳み込み層では、同じフィルタを画像全体に適用します。これを重み共有と呼びます。
この仕組みにより、
- パラメータ数を大幅に削減できる
- 同じ特徴を画像内の異なる位置で検出できる
という利点が得られます。
なお、畳み込み演算自体は平行移動に対して等変(equivariant)な性質を持ちます。
つまり、入力がずれれば出力の特徴マップも同じだけずれます。
その後にプーリングなどを組み合わせることで、小さな位置ずれに対する頑健性が高まります。
活性化関数(ReLU)の役割
畳み込み層の出力には、通常ReLU(Rectified Linear Unit)などの活性化関数が適用されます。
ReLU(x) = max(0, x)
ReLUの主な役割は以下の通りです。
- 非線形性を導入し、表現力を高める
- 計算が軽く、学習が安定しやすい
- 深いネットワークで問題になりやすい勾配消失を緩和する
現在のCNNにおいて、ReLUは事実上の標準的な選択肢となっています。
ダウンサンプリング(Pooling / Strided Convolution)
特徴マップのサイズを縮小するために、プーリング層やストライド付き畳み込みが使われます。
主な目的
- 計算量とメモリ使用量の削減
- ノイズへの耐性向上
- 過学習の抑制
代表的な方法には次があります。
- Max Pooling
- Average Pooling
- ストライド付き畳み込み
- Global Average Pooling(最終段)
近年のモデルでは、Max Poolingに限定せず、設計目的に応じて使い分けるのが一般的です。
分類部(全結合層・グローバルプーリング)
畳み込み層によって抽出された特徴は、最終的に分類のために統合されます。
- 従来型:全結合層(Fully Connected Layer)
- 近年主流:Global Average Pooling → 全結合層
この部分では、「抽出された特徴の組み合わせが、どのクラスに最も近いか」を判断します。
出力層と確率の扱い
多クラス分類の場合
単一の正解クラスを持つ問題では、Softmax関数が用いられることが一般的です。
- 各クラスに属する確率を出力
- 出力の合計は1になる
多ラベル分類の場合
複数クラスが同時に正解となり得る場合は、
- Sigmoid関数
- Binary Cross Entropy
が使われるのが一般的です。
実装上は、数値安定性のためにSoftmaxを明示的に書かず、損失関数側で処理するケースも多く見られます。
CNNの学習プロセス
画像分類におけるCNNは、基本的に教師あり学習で訓練されます。
学習の流れ
- 画像を入力
- 出力と正解ラベルの誤差を計算
- 誤差逆伝播(Backpropagation)で重みを更新
- 最適化手法(SGD、Adamなど)で反復学習
このプロセスを通じて、フィルタの重みが徐々に最適化されます。
代表的なCNNベースの画像分類モデル
- LeNet
- AlexNet
- VGG
- ResNet
- EfficientNet
特にResNet以降は、非常に深いネットワークでも安定して学習できる設計が特徴です。
実務では、これらのモデルを事前学習済みモデルとして利用するケースが主流です。
転移学習の重要性
画像分類をゼロから学習させるには、大量のデータと計算資源が必要です。
そのため実務では、転移学習(Transfer Learning)が広く使われています。
一般的な手順
- 大規模データセットで学習済みモデルを利用
- 分類層をタスクに合わせて置き換え
- 必要に応じて一部層を微調整(Fine-tuning)
これにより、少量データでも高い精度を得やすくなります。
実務で注意すべきポイント
- クラス間のデータ数の偏り
- ラベルノイズの影響
- データ拡張による汎化性能の向上
- 精度と推論速度のバランス
- 運用環境(クラウド・エッジ)への適合性
CNNによる画像分類では、モデル構造だけでなくデータ設計が精度を大きく左右します。
まとめ
- CNNは画像の空間構造を活かして特徴を学習するモデル
- 畳み込み層が特徴抽出の中核
- 等変性とダウンサンプリングにより位置ずれに頑健
- 実務では転移学習がほぼ標準
- 精度だけでなく運用を含めた設計が重要
以上、CNNによる画像分類についてでした。
最後までお読みいただき、ありがとうございました。