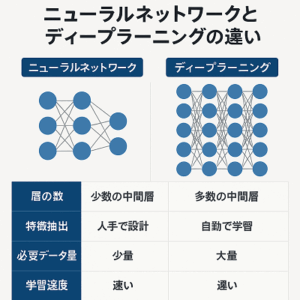
ディープラーニングにおける強化学習(Reinforcement Learning, RL)は、機械学習の一分野であり、エージェントが環境との相互作用を通じて最適な行動を学習するプロセスです。
この分野は、特に複雑な問題を解決する能力で注目を集めています。
目次
強化学習の基本概念
- エージェントと環境: エージェントは意思決定者であり、環境はエージェントが操作する世界です。エージェントは環境の状態を観測し、行動を選択します。
- 報酬: エージェントが特定の行動を取った結果として環境から得られるフィードバック。エージェントの目標は、長期にわたって最大の累積報酬を得ることです。
- ポリシー: エージェントがどのように行動を選択するかを定義する戦略。ポリシーは、環境の状態に基づいて最適な行動を決定します。
- 価値関数: ある状態(または状態と行動のペア)から得られる将来の報酬の期待値。価値関数を最大化することがエージェントの目標です。
- 探索と利用: エージェントは既知の情報を「利用」して報酬を最大化し、未知の行動を「探索」してより良い行動を見つけるバランスを取る必要があります。
ディープラーニングとの組み合わせ

ディープラーニングは強化学習において、特に複雑な環境や大量のデータが関わる場合に、エージェントが状態を理解し、価値関数やポリシーを学習するために使用されます。
深層ニューラルネットワークは、高次元の入力データ(例えば画像やビデオフレーム)から有意義な特徴を抽出し、エージェントがより複雑なタスクを学習できるようにします。
代表的なアルゴリズム
Q学習 (Q-Learning)
Q学習は、強化学習の基本的な形式の一つで、価値ベースのアプローチに分類されます。
- 概要: Q学習では、エージェントは「Qテーブル」と呼ばれる表を使用して、各状態と行動のペアに対する価値(Q値)を学習します。このQ値は、その状態から取ることができる特定の行動の期待される長期報酬を表します。
- アルゴリズムの流れ: エージェントは状態を観察し、Qテーブルに基づいて行動を選択します。行動の結果として報酬を受け取り、Q値を更新します。
Deep Q-Network (DQN)
Deep Q-Network(DQN)は、Q学習をディープラーニングと組み合わせたアルゴリズムです。
- 特徴: DQNは深層ニューラルネットワークを使用してQ値を近似します。これにより、高次元の入力空間(例えば画像)を扱うことが可能になります。
- 重要な技術:
- 経験再生 (Experience Replay): 過去の経験をランダムにサンプリングして学習することで、学習過程を安定化させます。
- ターゲットネットワーク: 定期的に更新される別のネットワークを使用して、学習中の急激なQ値の変化を抑制します。
Policy Gradients
Policy Gradientsは、ポリシーベースのアプローチで、直接ポリシー(行動を選択する確率分布)を最適化します。
- 特徴: この方法は、特定の状態で特定の行動を取る確率を直接モデル化し、報酬を最大化するようにポリシーを調整します。
- 利点: 連続的な行動空間や高次元の行動空間を扱うタスクに適しています。また、最適なポリシーが確率的(ランダム)である場合にも有効です。
Actor-Critic
Actor-Criticアルゴリズムは、ポリシーベースと価値ベースのアプローチを組み合わせたものです。
- 構成: 「Actor」はポリシーを学習し、どの行動を取るかを決定します。一方、「Critic」はその行動の価値(価値関数)を評価します。
- アプローチ: Actorは、Criticからのフィードバックを基にポリシーを更新します。Criticは、Actorの行動の結果として得られる報酬を評価し、それに基づいて価値関数を更新します。
応用分野

- ゲーム: AlphaGoやStarCraft IIなどの複雑なゲームで高い性能を示しています。
- 自動運転: 自動運転車が複雑な環境で最適な行動を学習するために使用されます。
- ロボティクス: ロボットが新しいタスクを学習するための手法として使用されています。
- 自然言語処理: 対話システムや翻訳システムなど、言語に基づく応用で利用されています。
課題と将来性
- サンプル効率: 強化学習は多くの試行を必要とするため、効率的な学習方法の開発が重要です。
- 一般化と転移学習: 異なるタスクや環境間で学習を転移させることは依然として課題です。
- 安全性と倫理: 実世界での応用において、安全な学習方法と倫理的な問題への対処が重要です。
強化学習とディープラーニングの組み合わせは、多くの可能性を秘めており、今後も様々な分野での進歩が期待されています。
以上、ディープラーニングの強化学習についてでした。
最後までお読みいただき、ありがとうございました。