
ニューラルネットワーク(Neural Network)は、人間の脳の神経構造を数理的に模したモデルであり、データからパターンを自動的に学習するアルゴリズムです。
ここでは、その学習の仕組み・理論・最適化手法・安定化技術・最新トレンドまでを、体系的にわかりやすく解説します。
目次
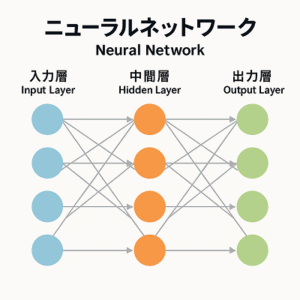
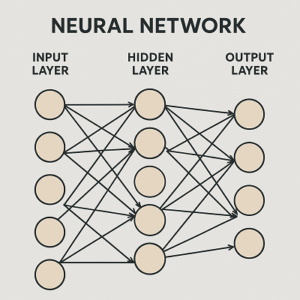
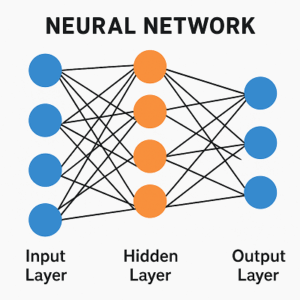
ニューラルネットワークの基本構造
ニューラルネットワークは、複数の「層(layer)」で構成されます。
一般的な構造は以下の通りです。
- 入力層(Input Layer)
入力データ(例:画像のピクセル値、テキストの埋め込みベクトルなど)を受け取る。 - 中間層(Hidden Layers)
各ノード(ニューロン)が前層の出力を受け取り、重み付きの線形変換と非線形活性化関数を通じて特徴を抽出。
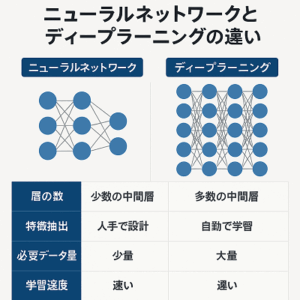
層を多く重ねることで「ディープラーニング(Deep Learning)」となります。 - 出力層(Output Layer)
最終的な推論結果を出力。分類タスクなら確率分布、回帰なら連続値を返します。
学習の根幹:誤差逆伝播法(Backpropagation)
ニューラルネットワークの学習は、「予測誤差を最小化するように重みを最適化する」ことです。
この最適化の中心にあるのが誤差逆伝播法(Backpropagation)です。
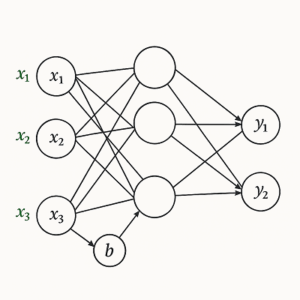
順伝播(Forward Propagation)
- 入力データをネットワークに通し、出力を得る。
- 各層では以下のような計算を行います:
( y = f(Wx + b) )
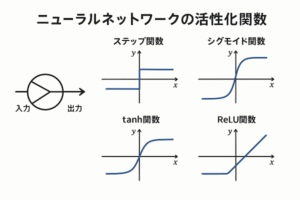
ここで、( W ):重み行列、( b ):バイアス、( f ):活性化関数(例:ReLU, GELU)。
損失関数(Loss Function)の計算
- 出力結果と教師ラベルの誤差を定量化します。
- 回帰タスク:平均二乗誤差(MSE)
- 多クラス分類:交差エントロピー損失(Cross Entropy)
- 二値分類:BCEWithLogitsLoss(シグモイド+バイナリ交差エントロピー)
誤差逆伝播(Backpropagation)
- 出力層の誤差を、ネットワークの各重みへ「偏微分」して伝播。
- 各重みが損失にどれほど寄与したかを勾配(gradient)として計算。
重みの更新(Optimization)
- 勾配に基づき、重みとバイアスを微調整して損失を減らす。
- 代表的な最適化アルゴリズム
- SGD(確率的勾配降下法)
- SGD with Momentum(慣性項を導入して局所最適を回避)
- Adam / AdamW(勾配のモーメントを利用。AdamWは正則化が理論的に改良され、現在主流)
- RMSProp / AdaGrad(学習率を各パラメータごとに自動調整)
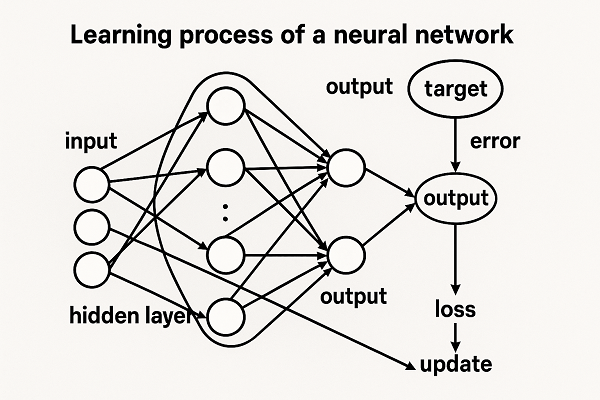
学習プロセスの全体像
ニューラルネットワークの学習は次のサイクルで進行します。
- 初期化:重みをランダム初期化(He初期化、Xavier初期化など)。
- 順伝播:入力から出力を算出。
- 損失計算:誤差を定量化。
- 逆伝播:誤差を勾配として伝播。
- 重み更新:最適化手法により更新。
- 繰り返し(エポック):全データを何度も反復して最適化。
学習を安定させるテクニック
ニューラルネットワークの学習は不安定になりやすいため、様々な正則化・正規化手法が使われます。
正則化(Regularization)
- L1/L2正則化(Weight Decay):重みの大きさを制限し、過学習を抑制。
→ AdamW では Weight Decay が理論的に分離されており、より安定。 - Dropout:学習時にランダムでニューロンを無効化し、汎化性能を高める。
バッチ正規化(Batch Normalization)
- 各層の出力を正規化して勾配を安定化。
- CNNではBatchNorm、TransformerではLayerNormが主流。
データ拡張(Data Augmentation)
- 学習データを人工的に増やし、過学習を防ぐ。
- 画像:回転・反転・カラージッター
- テキスト:単語の置換・削除
- 音声:時間伸縮・ノイズ追加
早期終了(Early Stopping)
- 検証損失が改善しなくなった時点で学習を停止し、過学習を回避。
学習率(Learning Rate)の最適化
学習率は最も重要なハイパーパラメータの一つで、「どれだけ速く最適化を進めるか」を決めます。
- 大きすぎる → 発散する可能性
- 小さすぎる → 収束が遅い
学習率の調整法
- Cosine Annealing:周期的に学習率を下げて再上昇。
- OneCycle Policy:学習初期にLRを上げて後半で急減。
- Warm-up:初期段階で徐々に学習率を上げ、安定化。
最新の学習アプローチ
近年ではニューラルネットワークの学習手法が大きく進化しています。
- Transformer系モデル:自己注意機構(Self-Attention)により系列データを並列処理。
- 自己教師あり学習(Self-Supervised Learning):ラベルなしデータから特徴を抽出(例:BERT, SimCLR)。
- 微調整(Fine-tuning)/ LoRA / QLoRA:大規模事前学習モデルを特定タスク向けに効率的に再学習。
- Diffusionモデル:前向き過程でノイズを付与し、逆過程を学習してノイズ除去を行う生成手法(Stable Diffusionなど)。
実務でのポイント
- 初期化:He/Kaiming初期化(ReLU系)やXavier初期化が標準。
- 活性化関数:ReLU, GELU, SiLU(Swish)が主流。
- 正規化の選択:モデル構造に応じてBatchNorm / LayerNormを使い分ける。
- 混合精度学習(AMP):16bit演算で高速化・省メモリ化。
- 再現性:乱数シードやCuDNN設定で制御可能。
まとめ
ニューラルネットワークの学習とは
「誤差を最小化するように重みを最適化するプロセス」
であり、その本質は勾配計算と最適化の繰り返しです。
しかし実務では、それを安定・効率的に進めるための正則化、正規化、学習率制御、データ拡張などの工夫が不可欠です。
深層学習の性能差は「アルゴリズムそのもの」よりも、学習をいかに安定化し、汎化性能を引き出すかにかかっています。
以上、ニューラルネットワークの学習方法についてでした。
最後までお読みいただき、ありがとうございました。