以下では、ファインチューニング(Fine-tuning) と 転移学習(Transfer Learning) の違いを、専門的かつ体系的に整理し、技術的正確性を重視してまとめています。
両者の概念的違い、関係性、学習範囲、モデル構造への影響、LLM 文脈での注意点などを詳細に解説します。
目次
基本的な定義の違い
転移学習(Transfer Learning)とは
- 大規模データで事前学習されたモデルの知識(特徴表現)を別タスクへ再利用する手法の総称。
- 主目的は
「既存の学習済み表現を新しいタスクへ効率よく移すこと」 にある。 - 通常は、ターゲットタスク用のデータで 何らかの再学習(最低限、出力層の学習) を行う。
例
画像分類モデルの初期層を流用し、別のクラス分類タスクへ適応させる。
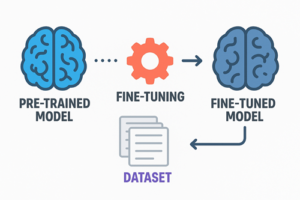
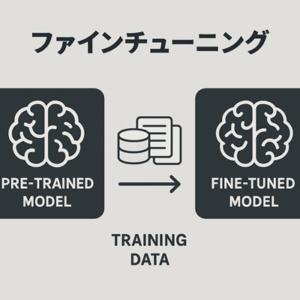
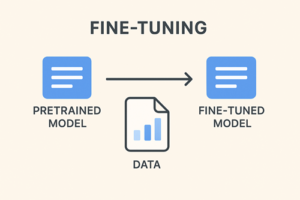
ファインチューニング(Fine-tuning)とは
- 転移学習の一形態で、
事前学習済みモデルのパラメータを、ターゲットタスクに合わせて再調整する学習手法。 - 再調整の範囲は以下のように複数存在する:
- 全層を再学習
- 上位層だけ再学習
- LoRA など追加層のみ学習(PEFT)
例
言語モデルを特定ドメインの文章コーパスで追加学習し、そのタスクに最適化する。
両者の関係性
- 転移学習は広い概念。
- ファインチューニングは転移学習に含まれる具体的手法の1つ。
転移学習には以下のような手法が含まれる。
- 特徴抽出(Feature Extraction)
- パラメータ凍結 + 新規層のみ学習
- 全層ファインチューニング
- LoRA / Adapter などの PEFT 手法
よって、
転移学習 ⊃ ファインチューニング
という関係が成り立つ。
“どこまでモデルを学習させるか” の観点での違い
| 項目 | 転移学習 | ファインチューニング |
|---|---|---|
| 再学習範囲 | 0〜一部の層(出力層のみ等) | 一部〜全層 |
| 目的 | 既存表現の再利用 | タスク特化への最適化 |
| 必要データ量 | 少ない〜中程度 | 中〜大量 |
| 計算コスト | 比較的低い | 中〜高 |
| モデルへの変更 | 出力層の交換だけで成立する場合も | 重みそのものを再調整 |
典型的な利用ケースの違い
転移学習が向くケース
- 訓練データが少ない
- 計算リソースを抑えたい
- 最終層だけ学習すれば十分なタスク
- 特徴抽出器として事前学習モデルを利用したい
ファインチューニングが向くケース
- 高精度が求められる
- タスク固有の複雑な知識が必要
- 長文生成やスタイル調整など、モデル挙動の細かな制御が必要
- 大量のドメイン特化データが利用可能
モデル構造の観点からの違い
転移学習
- 初期層の 一般的特徴(画像ならエッジ、言語なら構文など)をそのまま流用する。
- 再学習範囲は限定的で、モデルの大部分は固定のまま利用する。
→ モデルの知識を借りるイメージ
ファインチューニング
- 勾配計算を通じて、モデル内部のパラメータを更新する。
- 全層・部分層・LoRA層など、調整範囲を柔軟に選択可能。
→ モデルをタスク専用に“調整”するイメージ
LLM(大規模言語モデル)文脈での重要な違い
近年の LLM では、次の区別が特に重要です。
| 手法 | 特徴 |
|---|---|
| ゼロショット/プロンプト設計(In-context Learning) | パラメータを更新しない。プロンプトだけでタスク適応。 |
| RAG(Retrieval-Augmented Generation) | モデルは固定。外部データ検索で最新情報を補う。 |
| ファインチューニング | モデルパラメータを実際に更新してタスク適応。 |
ここでの注意点
プロンプト設計は、伝統的な意味の「転移学習」には分類されない。
ただし、「事前学習モデルをタスクに流用する」という広い意味では近い概念。
RAG は転移学習というより「運用アーキテクチャ」
- モデル内部は更新しないため、
狭義の転移学習(パラメータを更新する手法)には該当しない。
まとめ
転移学習:学習済みモデルの知識を新しいタスクへ再利用するための枠組み。
ファインチューニング:その枠組みの中で、パラメータを再学習してタスク最適化する手法。
以上、ファインチューニングと転移学習の違いについてでした。
最後までお読みいただき、ありがとうございました。