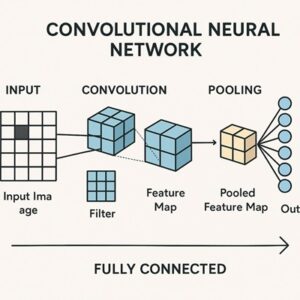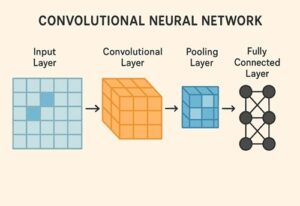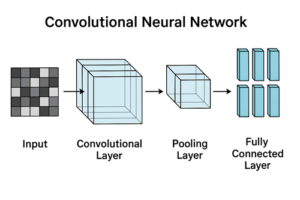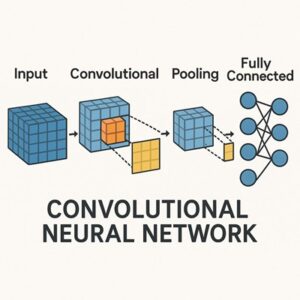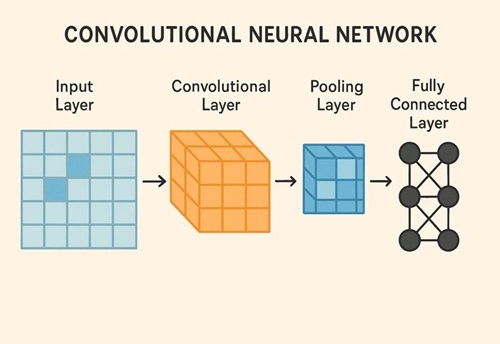

CNNとは何か
CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)は、画像の空間構造を活かしながら特徴を自動的に学習するために設計された深層学習モデルです。
画像を単なる数値の配列として扱うのではなく、
- 近接する画素同士の関係
- パターンの繰り返し
- 局所構造から大域構造への抽象化
といった性質を前提にモデル化されている点が、CNNの最大の特徴です。
なぜ画像処理にCNNが適しているのか
全結合ネットワークの限界
画像をそのまま全結合ネットワーク(MLP)に入力すると、
- 入力次元が非常に大きくなる
- パラメータ数が爆発的に増加する
- ピクセルの空間的な近さが考慮されない
という問題が生じます。
たとえば、224×224×3 の画像は約15万次元になり、このすべてを全結合で扱うのは現実的ではありません。
CNNを成立させている3つの設計原理
局所結合(Local Connectivity)
CNNでは、画像全体を見るのではなく、小さな領域(例:3×3や5×5)に限定して演算を行います。
これは、画像において重要な特徴(エッジや模様)が局所的な画素の関係から生じることを利用した設計です。
重み共有(Weight Sharing)
同じフィルタ(重み)を画像の異なる位置に適用します。
これにより、
- パラメータ数を大幅に削減できる
- 同じ特徴を画像のどこで検出しても同一視できる
という利点が得られます。
階層的特徴表現
CNNは層を重ねることで、
- 浅い層:エッジや単純なテクスチャ
- 中間層:角・模様・パーツ
- 深い層:より抽象的な構造(分類タスクでは物体に関連する特徴)
といった段階的な表現を学習する傾向があります。
※これは多くの画像分類モデルで観察される「典型的傾向」であり、すべてのタスク・モデルで厳密に同一になるわけではありません。
CNNを構成する主要な要素
畳み込み層(Convolution Layer)
畳み込み層では、小さなフィルタ(カーネル)を画像上でスライドさせ、内積計算を行うことで特徴マップ(Feature Map)を生成します。
- フィルタの値は学習によって最適化される
- エッジ検出器なども、人手ではなく自動的に獲得される
ここがCNNの中核部分です。
活性化関数(主にReLU)
多くのCNNでは ReLU(Rectified Linear Unit)が使われます。
ReLU(x) = max(0, x)
役割は以下の通りです。
- 非線形性の導入
- 勾配消失問題の緩和
- 計算の単純化による高速化
ダウンサンプリング(Pooling / Stride)
画像の空間サイズを縮小するために、
- Max Pooling
- Average Pooling
- ストライド付き畳み込み
などが用いられます。
これらの処理により、
- 計算量の削減
- 特徴の要約
- 小さな平行移動に対する頑健性の向上
が得られます。
※「完全な位置不変性」を保証するものではなく、あくまで局所的なズレに対して影響を受けにくくなる、という意味です。
出力層(全結合層とは限らない)
従来のCNNでは全結合層が使われてきましたが、近年では
- Global Average Pooling(GAP)
- 1×1 畳み込み
- 小規模な線形層
などを組み合わせ、全結合層を最小化または省略する設計も一般的です。
出力と損失関数はタスク依存
- 単一ラベル分類:Softmax
- 多ラベル分類:Sigmoid
- 類似度学習:専用の損失関数(ArcFace 等)
CNN自体は「特徴抽出器」であり、最終出力の形式はタスクによって変わります。
代表的なCNNアーキテクチャ
- LeNet:初期のCNN(手書き数字認識)
- AlexNet:大規模画像認識の転換点
- VGG:単純で深い構造
- ResNet:スキップ接続により超深層化を実現
- ConvNeXt:CNNをTransformer的設計思想で再構築
CNNの強みと限界
強み
- 少〜中規模データでも安定しやすい
- 計算効率が高い
- 軽量モデルが作りやすい
限界
- 回転・大きな視点変化には工夫が必要
- 大規模データではViT系が優位な場合もある
ただし、データ拡張や構造的工夫により、これらの弱点は実務上かなり緩和可能です。
現在の位置づけ
CNNは「古い技術」ではありません。
- ViTと競合する領域
- ハイブリッド構成
- 軽量・高速推論用途
など、現在も第一線で使われ続けています。
まとめ
CNNとは、
画像の局所構造を活かし、特徴を階層的に学習するための深層学習モデル
です。
- 畳み込み:特徴抽出
- ダウンサンプリング:要約と頑健性
- 出力設計:タスク依存
この考え方は、現在の画像AIの基礎であり続けています。
以上、CNNによる画像処理についてでした。
最後までお読みいただき、ありがとうございました。