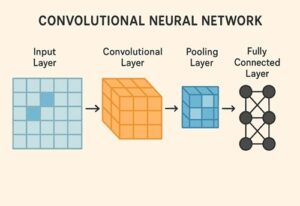
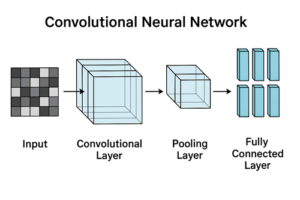
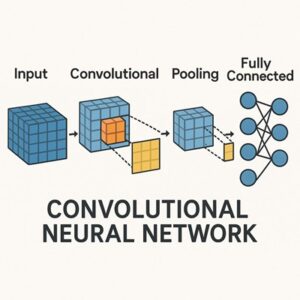
CNN(Convolutional Neural Network)とViT(Vision Transformer)は、いずれも画像認識分野で広く使われている代表的な深層学習モデルです。
しかし両者は、画像の捉え方そのものが根本的に異なるという点で、大きな違いがあります。
本記事では、仕組み・学習特性・計算量・実務での使い分けまで含めて、両者の違いを体系的に整理します。
根本的な思想の違い
まず最初に、両者の違いを一文で表すと次のようになります。
- CNN:画像を「局所的な特徴の積み重ね」として理解するモデル
- ViT:画像を「パッチの集合=トークン列」として理解し、全体の関係性を重視するモデル
CNNは「画像らしさ」を前提に設計されたモデルであり、ViTはもともと自然言語処理で使われていたTransformerを画像に応用したモデルです。
この出自の違いが、さまざまな性質の差につながっています。
入力の扱い方の違い
CNNの場合
CNNは入力画像を H×W×C(高さ×幅×チャンネル) の2次元グリッドとしてそのまま扱います。
3×3 や 5×5 といった小さなフィルタ(畳み込みカーネル)を画像全体に適用し、近傍ピクセルのパターンから特徴を抽出していきます。
この処理により、エッジや色の変化といった局所的な情報を効率よく捉えることができます。
ViTの場合
ViTでは、画像をいったん 固定サイズのパッチ(例:16×16ピクセル)に分割します。
- 画像をパッチに分割
- 各パッチを一次元ベクトルに変換
- 線形変換によって埋め込み(embedding)を生成
- それらを トークン列 としてTransformerに入力
さらに、Transformerは順序情報を自動で扱えないため、位置埋め込み(positional embedding) を加えて「どのパッチがどこにあったか」をモデルに教えます。
つまりViTは、画像を「単語の並び」に近い形で処理していると考えると理解しやすいでしょう。
特徴抽出の仕組みの違い
CNN:畳み込みによる局所特徴の階層化
CNNの最大の特徴は、以下のような強い画像向けの帰納バイアスを持っている点です。
- 近くのピクセル同士は意味的に関係が深い(局所性)
- 同じ特徴は画像内のどこに現れても同じ意味を持つ(重み共有)
- 小さな特徴を積み上げることで、大きな概念を表現できる(階層性)
畳み込み操作は 平行移動等価性(translation equivariance) を持ち、入力画像が少し移動すれば、特徴マップも同じように移動します。
さらにプーリングやグローバル平均プーリングなどを組み合わせることで、位置ずれに対して頑健な表現を獲得できます。
ViT:自己注意によるグローバルな関係性の学習
ViTの中核となるのは Self-Attention(自己注意) です。
自己注意では、各トークン(パッチ)が他のすべてのトークンを参照し、「どのパッチが重要か」「どのパッチ同士が関係しているか」を動的に学習します。
この仕組みにより、
- 離れた領域同士の関係
- 画像全体の整合性や文脈
を初期段階から直接モデル化しやすい、という特徴があります。
一方で、CNNのような局所性や平行移動等価性は設計としては強く組み込まれておらず、主に学習によって獲得されます。
帰納バイアスの強さとデータ効率
CNNの特徴
CNNは画像向けの前提条件が強く組み込まれているため、
- 比較的少量のデータでも学習しやすい
- 学習が安定しやすい
という利点があります。これは長年、画像認識でCNNが主流だった大きな理由のひとつです。
ViTの特徴
ViTはCNNほど強い画像向け帰納バイアスを持たないため、
- 大規模データや事前学習があると非常に強い
- 小規模データのみだと学習が難しい場合がある
という性質を持ちます。
ただし近年では、蒸留(DeiT)や強力なデータ拡張、正則化手法の発展により、小規模データでも十分に実用的な性能を出せるケースが増えています。
計算量とスケーラビリティ
CNN
- 計算は主に局所領域に限定される
- 高解像度でも比較的スケールしやすい
- モバイルやリアルタイム用途に向いた軽量モデルが豊富
ViT
- 自己注意はトークン数 N に対して O(N²) の計算量になりやすい
- 高解像度画像では計算コストが急増する
この課題に対して、Swin Transformer のように「局所ウィンドウ注意+階層構造」を採用した派生モデルが提案され、実用性が大きく向上しています。
実務での使い分けの目安
CNNが向いているケース
- データ量が限られている
- 推論速度やモデルサイズが重要
- エッジデバイスやモバイル環境
- 安定性と実績を重視したい場合
ViTが向いているケース
- 大規模な事前学習モデルを利用できる
- 精度最優先のタスク
- 画像全体の関係性が重要な問題
- 将来的にデータや計算資源をスケールさせたい場合
まとめ
- CNNは、局所性・平行移動等価性・階層性といった画像特有の構造を強く仮定したモデルであり、少量データや軽量推論に強い
- ViTは、画像をパッチ列として扱い、自己注意によってグローバルな関係性を学習するモデルで、大規模事前学習と相性が良くスケーラブル
- 実務では「データ量」「推論制約」「解像度」「事前学習の有無」を基準に選択するのが合理的
以上、CNNとVITの違いについてでした。
最後までお読みいただき、ありがとうございました。