
CNN(Convolutional Neural Network)とYOLO(You Only Look Once)は、どちらも画像認識分野で重要な技術ですが、同列に比較される概念ではありません。
両者の違いを正しく理解するためには、「役割の階層」が異なることを押さえる必要があります。
結論から言えば、
- CNNは画像理解のための基盤となるニューラルネットワーク構造
- YOLOはCNNを利用して物体検出を実現するアルゴリズム
という関係にあります。
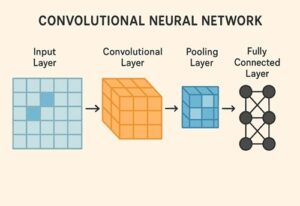
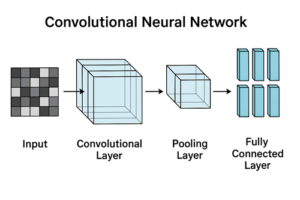
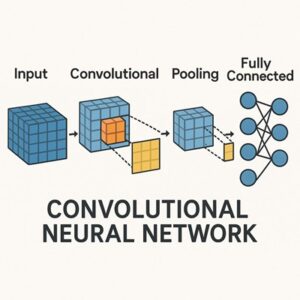
CNNとは何か
CNNは、画像や映像データから特徴を自動的に抽出するために設計されたニューラルネットワーク構造です。
畳み込み演算を用いることで、画像中のエッジや模様、形状といった局所的特徴を段階的に学習できる点が最大の特徴です。
CNNの基本的な役割
CNNの本質的な役割は以下の2点に集約されます。
- 空間構造を保ったまま特徴を抽出すること
- 抽出した特徴を高次の表現へと変換すること
この特性により、CNNは以下のようなタスクで広く利用されています。
- 画像分類
- 画像の特徴量抽出
- セグメンテーション
- 物体検出モデルのバックボーン
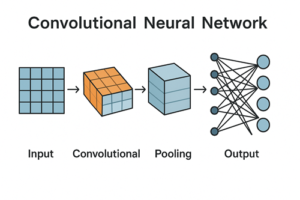
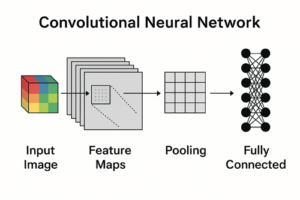
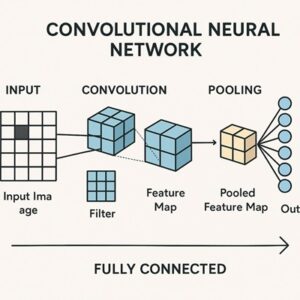
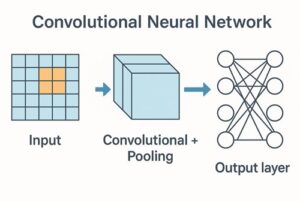
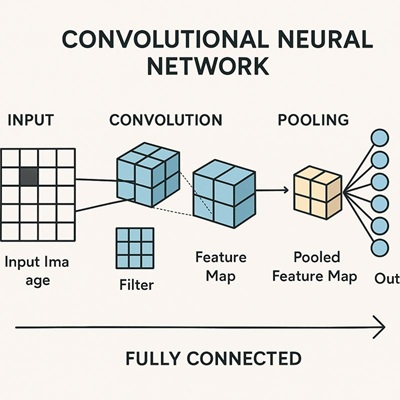
CNNの典型的な構成
一般的なCNNは次のような層構造を持ちます。
- 畳み込み層:画像から局所的特徴を抽出
- プーリング層:特徴を集約し、位置ずれへの耐性を高める
- 全結合層:抽出された特徴をもとに最終的な判断を行う
ただし、これはあくまで代表的な構成例であり、CNNそのものが「分類専用」であることを意味するわけではありません。
CNNに関する誤解と正しい理解
「CNNは画像分類しかできない」という誤解
CNNはしばしば「画像全体を1つのクラスに分類するモデル」として説明されますが、これは典型的な使われ方の一例にすぎません。
CNNはあくまで「特徴抽出のための構造」であり、出力の設計次第でさまざまなタスクに対応可能です。
位置検出や複数物体検出について
「CNN単体では物体の位置検出や複数物体検出はできない」と断言するのは正確ではありません。
正確には、
- 分類用として設計されたCNN(クラス1つを出力する形)のままでは
- 物体の位置
- 複数物体の同時検出
を直接出力できない
という意味になります。
出力層や損失関数を検出用に拡張すれば、CNNを用いた物体検出は可能であり、実際にYOLOを含む多くの検出モデルはCNNを基盤としています。
YOLOとは何か
YOLO(You Only Look Once)は、物体検出(Object Detection)に特化したアルゴリズムです。
物体検出とは、
- 画像内に「何が写っているか」
- それが「どこにあるか」
を同時に推定するタスクを指します。
YOLOの設計思想
YOLOの最大の特徴は、
- 画像を一度の推論で処理し
- 物体の位置とクラスを同時に予測する
という点にあります。
従来の手法では、「候補領域の生成 → 分類 → 位置調整」といった複数段階の処理が必要でしたが、YOLOはこれらを単一のニューラルネットワークに統合しています。
YOLOの内部構造
YOLOは内部でCNNを用いて画像特徴を抽出し、その特徴をもとに以下の情報を出力します。
- バウンディングボックスの座標(位置とサイズ)
- 物体が存在する確からしさ(objectness)
- クラス確率
これらを組み合わせることで、最終的な検出結果を決定します。
CNNとYOLOの違いを正確に比較する
役割の違い
- CNN
- 画像特徴を抽出するための基盤技術
- 単体ではタスクを規定しない
- YOLO
- CNNを用いて物体検出を実現するアルゴリズム
- 入力と出力の形式が明確に定義されている
出力の違い
- CNN(分類用の典型構成)
- クラスラベルのみを出力
- YOLO
- クラス
- 位置情報(バウンディングボックス)
- 物体らしさのスコア
を同時に出力
実装レベルでの違い
CNNは「部品」に近い存在であり、YOLOは「完成されたアプリケーション寄りのモデル」と言えます。
YOLOが高速とされる理由
YOLOがリアルタイム処理に強い理由は、以下の点にあります。
- 検出処理を単一ネットワークで完結させている
- 画像全体を同時に処理するため並列化しやすい
- エンドツーエンドで最適化できる設計
このため、監視カメラ映像や自動運転など、速度が重視される用途で多く採用されています。
以上、CNNとYOLOの違いについてでした。
最後までお読みいただき、ありがとうございました。