
CNN(畳み込みニューラルネットワーク)の設計において、フィルタ数(出力チャネル数)をどう決めるかは、モデル性能・計算コスト・汎化性能のすべてに影響する重要な設計要素です。
しかし、この値には一意の正解は存在せず、多くの場合は経験則と検証の積み重ねによって最適化されます。
本稿では、
- フィルタ数の意味
- なぜ定番パターンが存在するのか
- 少なすぎる/多すぎる場合に何が起きるのか
- 実務でどう調整すべきか
を誤解のない形で整理します。
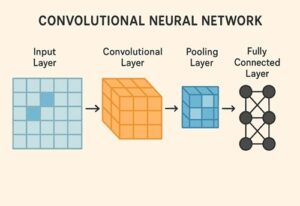
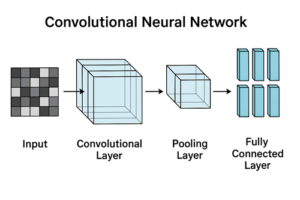
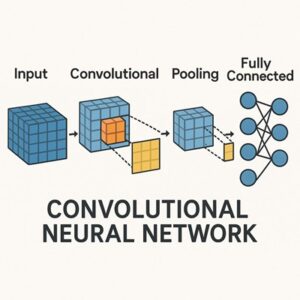
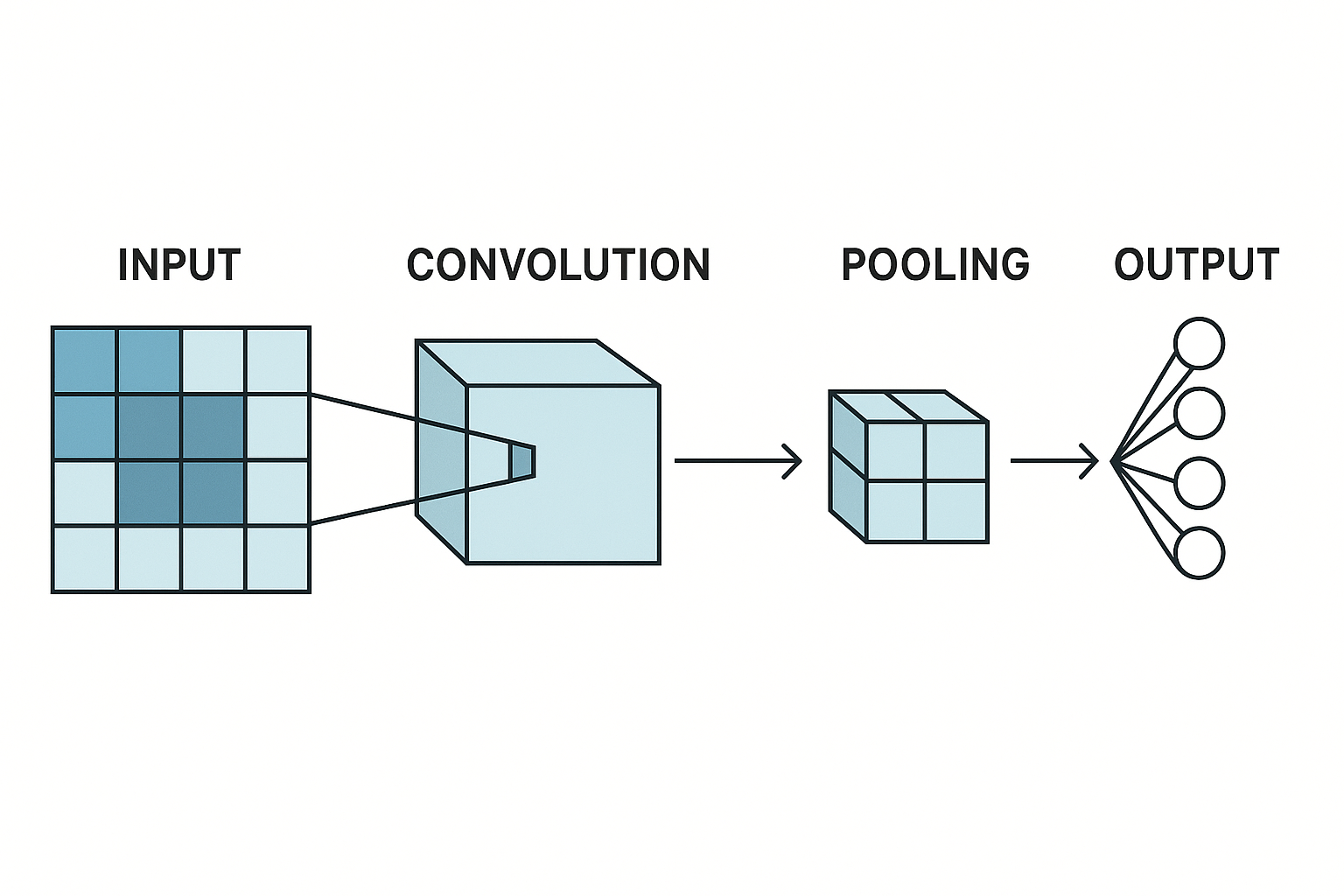
フィルタ数とは何か(基本の確認)
CNNにおけるフィルタ数 = 出力チャネル数です。
- 1つのフィルタ
→ 入力特徴マップ全体に対して畳み込みを行い
→ 1枚の特徴マップ(1チャネル)を出力する - フィルタ数が N
→ 出力は N チャネルの特徴マップになる
つまり、フィルタ数とは
その層で同時に学習・表現できる特徴の種類の数
と考えて問題ありません。
※通常の畳み込み(groups=1)を前提としています。Depthwise Convolution などでは意味合いが変わる点には注意が必要ですが、一般的なCNN設計ではこの理解で十分です。
なぜ「最適なフィルタ数」は理論的に決まらないのか
フィルタ数に絶対的な正解が存在しない理由は以下にあります。
- データの種類・複雑さが異なる
- 学習データ量が異なる
- タスクの難易度(単純分類/検出/分割など)が異なる
- 計算資源(GPUメモリ・推論速度)の制約が異なる
- 正則化やデータ拡張の強さが異なる
このため、実務では
まず無難な構成から始め、学習曲線を見て調整する
というアプローチが最も効率的です。
よく使われるフィルタ数の基本パターン
倍増ルール(経験則)
多くのCNNでは、層が深くなるにつれてフィルタ数を増やします。
代表的な例は次のような構成です。
32 → 64 → 128 → 256 → 512また、軽量モデルや小規模データセットでは:
16 → 32 → 64 → 128といった構成も一般的です。
なぜ深くなるほどフィルタ数を増やすのか
- 浅い層
→ エッジ・色・単純なパターンなど、低レベル特徴
→ 少数のフィルタで十分 - 深い層
→ 形状・構造・意味的特徴など、高レベル特徴
→ より多様な組み合わせが必要
その結果、
空間解像度を下げながら、チャネル方向で表現力を増やす
という設計が自然に生まれます。
入力サイズとフィルタ数の関係
小さな入力画像(例:28×28、32×32)
- MNIST、CIFAR-10 など
- 例
Conv1: 32
Conv2: 64
Conv3: 128入力が小さい場合でも深いモデルは成立しますが、
- ダウンサンプリングが早すぎると空間情報が失われやすい
- フィルタ数を増やしすぎると過剰なモデル容量になりやすい
という点に注意が必要です。
大きな入力画像(例:224×224)
- ImageNet 系タスク
- 例
64 → 128 → 256 → 512高解像度画像では、
- 抽出すべき特徴が多い
- 空間情報を段階的に圧縮しながら、表現力を増やす必要がある
ため、チャネル数を多めに設定するのが一般的です。
フィルタ数とパラメータ数・計算量の関係
畳み込み層のパラメータ数
通常の畳み込み層(groups=1)のパラメータ数は次式で表されます。
カーネルサイズ × 入力チャネル数 × 出力チャネル数例
- 3×3 カーネル
- 入力 64ch → 出力 128ch
3 × 3 × 64 × 128 = 73,728重要な注意点
- 出力チャネル(フィルタ数)だけを2倍にする
→ パラメータ数はほぼ2倍 - 層全体でチャネル数を2倍にする設計
→ 次層では入力チャネルも増えるため
→ パラメータ数・計算量は 約4倍規模 になることが多い
この違いを意識しないと、モデルが急激に重くなります。
フィルタ数が少なすぎる場合
起こりやすい現象
- 学習精度・検証精度ともに低い
- ロスが早い段階で頭打ちになる
原因
- モデルの表現力不足(アンダーフィッティング)
対策
- フィルタ数を段階的に増やす
- 層を深くする
- 高解像度を保つステージを増やす
フィルタ数が多すぎる場合
起こりやすい現象
- 学習精度は高いが検証精度が伸びない
- 学習が遅い、メモリ不足が発生する
原因
- モデル容量過多
- データ量に対して冗長な表現
※ただし、大規模データ・強い正則化・強力なデータ拡張がある場合は、チャネル数を増やした方が汎化性能が向上するケースも多い点には注意が必要です。
タスク別のフィルタ数設計の目安
単純な画像分類
32 → 64 → 128物体検出・セグメンテーション
64 → 128 → 256 → 512軽量・リアルタイム用途
16 → 32 → 64加えて、Depthwise Convolution や Bottleneck 構造を併用して計算量を抑えるのが一般的です。
実務での現実的な決め方(推奨手順)
まずは定番構成から始める
学習曲線(train / val)を確認する
フィルタ数を一段階ずつ調整する
- 64 → 96 → 128
- 128 → 192 → 256
精度・速度・メモリのバランスで判断する
まとめ
- フィルタ数は「特徴の種類の数」を決める重要なハイパーパラメータ
- 理論的な唯一解は存在しない
- 基本は「浅い層は少なく、深い層は多く」
- 倍増ルールは強力な初期解だが、条件付きの経験則
- 調整は学習曲線を見ながら段階的に行うのが最短ルート
以上、CNNのフィルタ数の決め方についてでした。
最後までお読みいただき、ありがとうございました。