
目次
ニューラルネットワークの基本構造
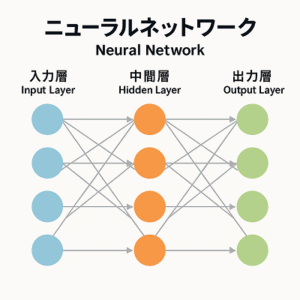
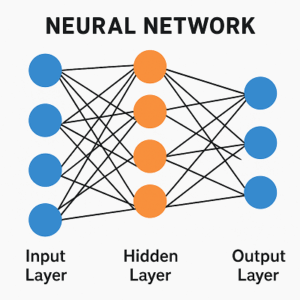
ニューラルネットワーク(Neural Network)は、人間の脳の神経細胞(ニューロン)を数理的に模したモデルで、複数の層(Layer)から構成されます。
構造の基本形は次のようになります。
入力層(Input Layer)
↓
隠れ層(Hidden Layers)
↓
出力層(Output Layer)
データはこの層を順に通過し、各層で特徴の抽出や変換を行いながら、最終的な予測や分類に至ります。
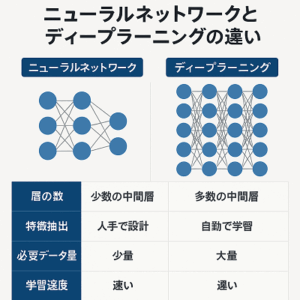
特に「隠れ層」が多層に積み重なったモデルがディープラーニング(Deep Learning)と呼ばれます。
各層の役割と特徴
入力層(Input Layer)
入力層はデータをネットワークに受け渡す入口にあたります。
ここでは実際の「学習」は行われず、単に入力値を次の層へ伝える役割です。
ただし、埋め込み層(Embedding Layer)や最初の畳み込み層のように、入力直後で数値を学習可能なベクトル空間に変換するケースもあります。
したがって、「入力層」というより「入力処理部」と捉えるほうが現代的です。
隠れ層(Hidden Layers)
ニューラルネットワークの中核であり、入力を特徴空間に変換し、抽象的なパターンを学習する層です。
ここでは線形変換と非線形変換(活性化関数)を組み合わせて表現力を高めています。
主な種類と役割
| 層の種類 | 概要 | 主な用途 |
|---|---|---|
| 全結合層(Dense Layer) | 各ノードが前層すべてのノードと接続。 | 一般的な表形式データ・最終分類部など。 |
| 畳み込み層(Convolutional Layer) | 小さなカーネルを用いて局所的特徴を抽出。 | 画像・映像認識(CNN系)。 |
| プーリング層(Pooling Layer) | 特徴マップを圧縮し、位置ずれに強くする。 | CNNで利用。ただし近年はストライド付き畳み込みや**Global Average Pooling(GAP)**が主流。 |
| 再帰層(Recurrent Layer) | 時系列的依存を考慮し、過去の隠れ状態を次時刻に伝搬。 | 時系列データ・自然言語処理(RNN/LSTM/GRU)。 |
| 正規化層(Normalization Layer) | 学習を安定化させるため出力をスケーリング。 | CNNではBatchNorm、TransformerではLayerNormが主流。 |
| ドロップアウト層(Dropout Layer) | 学習時に一部のノードを無効化し過学習を抑制。 | 特に全結合層やTransformer内で有効。 |
出力層(Output Layer)
出力層は最終的な予測結果を生成する層です。
タスクの種類によってノード数と活性化関数が変わります。
| タスク | 出力ノード数 | 主な活性化関数 | 一般的な損失関数 |
|---|---|---|---|
| 二値分類 | 1 | Sigmoid | Binary Cross Entropy(BCE) or BCEWithLogitsLoss |
| 多クラス分類 | クラス数 | Softmax | Cross Entropy |
| 多ラベル分類 | ラベル数 | Sigmoid(各ラベル独立) | BCE |
| 回帰 | 1または複数 | なし(線形) | MSE, MAE, Huberなど |
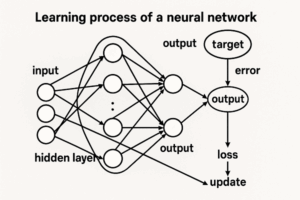
層内部の計算プロセス
各層では、次の手順で処理が行われます。
- 線形変換
- 非線形変換(活性化関数)
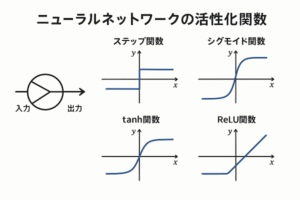
よく用いられる活性化関数- ReLU:(汎用的で高速)
- LeakyReLU / GELU / Swish:ReLU改良版
- Sigmoid / Tanh:古典的だが近年は限定的用途
- 次層へ出力
層の深さと特徴抽出の抽象度
層が深くなるほど、モデルはデータの抽象的特徴を学習します。
特に画像認識ではこのような階層構造が見られます。
| 層 | 抽出される特徴 |
|---|---|
| 初期層 | エッジ・線・色などの低次特徴 |
| 中間層 | 模様・形・構造などの中間特徴 |
| 深層部 | 顔・物体・意味概念などの高次特徴 |
ただし、Transformer系モデルでは早期層から広範な依存関係を自己注意(Self-Attention)で捉えるため、
「抽象化の深さ」は必ずしも層順に一致しません。
学習を安定させる補助層
学習を効率化・安定化するために、次のような層や手法が導入されます。
- Batch Normalization:CNNやMLPで標準。勾配消失を防ぎ学習を高速化。
- Layer Normalization:TransformerやRNNで使用。バッチ依存を排除。
- Dropout:過学習抑制。位置により効果が異なる。
- Residual Connection(残差接続):勾配伝搬を改善。ResNetやTransformerで基本構造。
層設計の考え方と実践的ガイドライン
データ種別別の推奨構造
| データタイプ | 推奨アーキテクチャ | 補足 |
|---|---|---|
| 画像 | CNN(ResNet/EfficientNet) or Vision Transformer | プーリングはGAPを使用 |
| テキスト・NLP | Transformer(BERT/DistilBERTなど) | RNNは用途限定的 |
| 時系列 | GRU/TCN/Transformer | 長期依存ならTransformer系 |
| 表形式(Tabular) | シンプルなMLP(2〜4層) | CatBoost/LightGBMとの併用検討 |
| 生成モデル | Autoencoder / GAN / Diffusion系 | Encoder–Decoder構造が基本 |
層の深さと幅
- 表形式データ:2〜4層で十分。
- 画像・言語モデル:数十〜百層規模が一般的(残差接続・正規化により学習可能)。
最適化と安定化
- 初期化:He / Xavier 初期化。
- 最適化手法:AdamWがデファクトスタンダード。
- 正則化:Weight Decay・Early Stopping・データ拡張。
- 学習率スケジューラ:Cosine Annealing, OneCycle等。
現代的モデル例と層構成
| モデル | 主な構成要素 | 主な用途 |
|---|---|---|
| CNN | 畳み込み + 正規化 + 活性化 + プーリング | 画像認識・医用画像解析 |
| ResNet | 残差ブロック(Conv + BN + ReLU + Skip) | 深層画像分類 |
| Transformer | Self-Attention + FFN + 残差 + LayerNorm | NLP・音声・画像・生成AI |
| Autoencoder | Encoder/Decoder層 | 次元圧縮・特徴抽出 |
| GAN | Generator/Discriminator | 画像・音声生成 |
| ViT / BERT | Transformerブロックの多層積み上げ | 視覚・言語タスク全般 |
まとめ
- 層(Layer)はニューラルネットの知的構造そのもの。
各層がデータを段階的に変換し、抽象化していくことで、人間に近い認識や判断を実現します。 - 入力から出力までの「層の積み重ね」は、学習の流れ=情報の抽象化のプロセスです。
- 近年はCNNやRNNの枠を超え、Transformer構造が画像・音声・テキストの全分野に浸透しつつあります。
- モデル設計では、データの性質に合わせた層構成・正規化・最適化手法の選択が成功の鍵です。
以上、ニューラルネットワークの層についてでした。
最後までお読みいただき、ありがとうございました。