ディープラーニングにおける「特徴量」について詳しく説明します。
ディープラーニングは、データからパターンを学習し、これを基に予測や分類を行うための強力なツールです。
この過程で、特徴量が中心的な役割を果たします。
目次
特徴量とは何か?

特徴量(Feature)は、データ分析、機械学習、そしてディープラーニングにおいて非常に重要な概念です。
特徴量はデータを表現する際の個々の観測可能な属性や量を指し、これらの特徴量を使ってデータから意味ある情報を抽出し、予測や分類を行います。
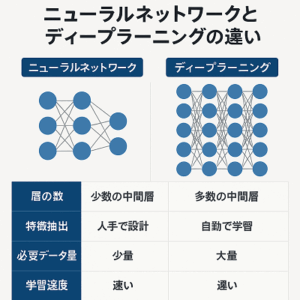
特徴量の基本概念
- データの属性: 特徴量はデータセット内の個々の属性を表します。たとえば、顧客データセットの特徴量には年齢、性別、購入履歴などが含まれることがあります。
- 入力変数: 機械学習モデルにおいて、特徴量は入力変数として扱われ、これらを基にモデルが学習を行います。
特徴量の重要性
- モデルの性能: 良質な特徴量はモデルの精度を大きく左右します。不適切な特徴量はモデルのパフォーマンスを低下させる可能性があります。
- 解釈可能性: 特徴量が明確であるほど、モデルの予測や決定の背後にある理由を理解しやすくなります。
ディープラーニングにおける特徴量の役割
- データの表現: ディープラーニングモデルは、生のデータを直接処理するのではなく、データを特徴量として表現します。これにより、データの本質的な特性を捉え、より効率的な学習が可能になります。
- 自動特徴抽出: 従来の機械学習モデルでは、特徴量を手動で設計する必要がありましたが、ディープラーニングはデータから自動的に特徴量を学習します。この過程を「特徴学習」(Feature Learning)または「表現学習」(Representation Learning)と呼びます。
ディープラーニングの特徴量の種類
低レベル特徴量
- 基本的な属性: これらはデータの最も基本的な側面を表し、直接的な物理的または視覚的な特性を捉えます。
- 例: 画像データでは、エッジ(線の境界)、角、色、テクスチャなどが低レベル特徴量に該当します。音声データでは、音の周波数や振幅が低レベル特徴量となり得ます。
中間レベル特徴量
- 複合的な属性: これらは低レベル特徴量の組み合わせによって形成され、より複雑なパターンや構造を示します。
- 例: 画像の場合、特定の形状やパターン(たとえば車輪や窓の形状)が中間レベルの特徴量です。音声データでは、特定の音節や音声のトーンが中間レベル特徴量になります。
高レベル特徴量
- 抽象的な概念: 高レベル特徴量はデータの非常に抽象的な側面を表し、具体的な物理的特性を超えた概念的な情報を含みます。
- 例: 画像データでの「顔認識」や「シーンの認識」、音声データでの「話者の識別」や「感情の認識」などが高レベル特徴量です。
ディープラーニングと従来の特徴量抽出の違い

- 自動化と適応性: ディープラーニングは、特定のタスクに依存せず、データから自動的に特徴量を学習する能力を持ちます。
- 階層的な学習: ディープラーニングモデルは、多層のアーキテクチャを通じて、低レベルから高レベルまでの特徴量を段階的に抽出します。
まとめ
ディープラーニングにおける特徴量は、データの複雑な構造とパターンを理解するための鍵となります。
これにより、データの本質的な特性を捉え、より精度の高い予測や分類が可能になるため、この分野の中心的な要素となっています。
特徴量の自動抽出能力は、ディープラーニングを従来の機械学習手法と区別する重要な特徴の一つです。
以上、ディープラーニングの特徴量についてでした。
最後までお読みいただき、ありがとうございました。