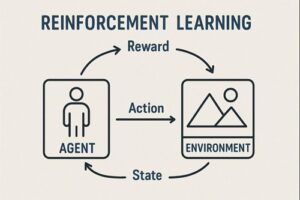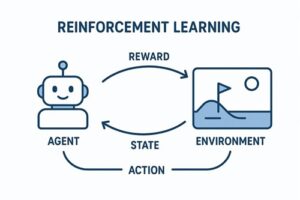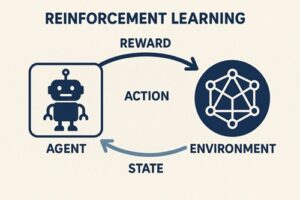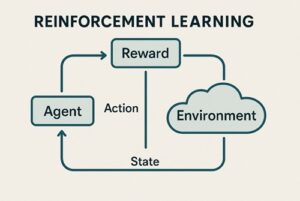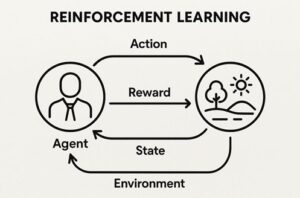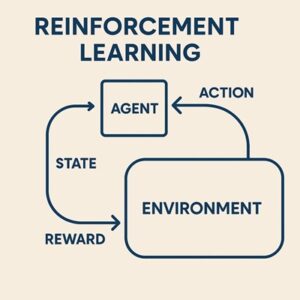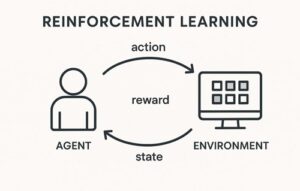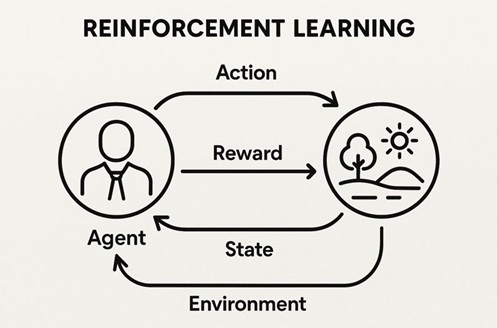

Q学習は、強化学習における代表的な学習手法で、「ある状況で、ある行動を取ることが、将来的にどれだけ得か」を数値として学習していく方法です。
ここで重要なのは、
- 環境のルールや仕組みを事前に知らなくてもよい
- 実際に行動して得た結果(成功・失敗)だけを使って学習する
という点です。そのため、Q学習は「モデルフリー強化学習」に分類されます。
Q値の意味
Q学習で扱う「Q値」とは、次のような意味を持つ値です。
- 今どんな状態にいるか
- そこでどの行動を選ぶか
この組み合わせに対して、「その行動を選んだ場合、今後トータルでどれくらい報酬が得られそうか」を数値で表したものがQ値です。
ポイントは、
- 目先の報酬だけでなく
- その後に続く将来の結果も含めて評価する
という点です。
つまりQ値は「短期的な得」ではなく「長期的な得」を表します。
Q学習はどのように学ぶのか
Q学習では、エージェントが環境の中で試行錯誤を繰り返します。
- 現在の状態を観測する
- 何らかの行動を選ぶ
- 行動の結果として、報酬と次の状態を受け取る
- 「今回の結果」と「将来の見込み」を使って、選んだ行動の評価を少し修正する
この「少し修正する」という点が重要で、Q学習は一度の経験ですべてを決めるのではなく、何度も同じような状況を経験しながら、評価を徐々に現実に近づけていきます。
将来の見込みをどう扱うか
Q学習の特徴は、「次の状態で最も良さそうな行動を取った場合」を常に基準として考える点にあります。
つまり、
- 実際に次にどの行動を取るかとは関係なく
- 「次の状態では、最善の行動を取ると仮定したらどうなるか」
を使って、現在の行動の価値を更新します。
この性質により、Q学習は「オフポリシー学習」と呼ばれます。
探索のためにランダムな行動を取っていても、学習自体は常に「最適に行動する前提」で進んでいきます。
探索と活用のバランス
Q学習では、次の2つをバランスよく行う必要があります。
- 活用:今までの学習結果を信じて、一番良さそうな行動を選ぶ
- 探索:まだ試していない行動をあえて試す
このバランスを取るためによく使われるのが「一定の確率でランダム行動を混ぜる」方法です。
学習の初期は探索を多めにし、学習が進むにつれて徐々に「一番良い行動」を選ぶ割合を増やしていく、という運用が一般的です。
ただし、探索を減らしすぎると、より良い行動を見つける前に学習が止まってしまう可能性があるため、探索の設計はQ学習の成否を左右します。
Q学習がうまくいくための前提条件
理論的にQ学習が最適な行動に近づくためには、いくつかの前提があります。
- 状態や行動の種類が有限であること
- すべての状態と行動の組み合わせが、十分な回数試されること
- 学習の更新幅が、学習の進行とともに適切に調整されること
これらが満たされていない場合、必ずしも最適な結果に収束するとは限りません。
実務や実験では、理論的な保証よりも実用的な性能を重視してパラメータを調整することが多いのが実情です。
Q学習の弱点と注意点
Q学習には強力な特徴がある一方で、注意すべき弱点もあります。
- 状態や行動が多くなると、すべての組み合わせを学習するのが難しくなる
- 評価値がばらついていると、実際よりも良く見積もってしまう傾向がある
- 報酬がゴールでしか得られないような問題では、学習が非常に遅くなる
これらの問題は、後述する発展手法につながります。
大規模問題への発展(DQN)
状態が画像や連続値のように複雑になると、Q値を表形式で管理するのは現実的ではありません。
その場合、Q値を直接覚える代わりに、ニューラルネットワークで近似する方法が使われます。
これがDQN(ディープQネットワーク)です。
DQNでは学習が不安定になりやすいため、
- 過去の経験をランダムに再利用する仕組み
- 学習の基準となる評価を一定期間固定する仕組み
といった工夫が組み込まれています。
過大評価への対処(Double DQN)
Q学習系の手法では、「一番良い行動」を基準に評価する性質上、実際よりも価値を高く見積もってしまうことがあります。
この問題を緩和するために考案されたのがDouble DQNです。
行動の選択と、その行動の評価を分離することで、評価の偏りを抑える仕組みになっています。
まとめ
Q学習は、
- 将来の報酬を見据えて行動の価値を学ぶ
- 環境の仕組みを知らなくても試行錯誤で学習できる
- 理論的な裏付けと実務的な応用の両方を持つ
という点で、強化学習の基礎かつ中核となる手法です。
一方で、探索設計や状態数の増大、評価の偏りといった課題もあり、それらを理解したうえで使うことが、Q学習を正しく扱うためのポイントになります。
以上、強化学習のQ学習についてでした。
最後までお読みいただき、ありがとうございました。