
割引率の本質的な役割
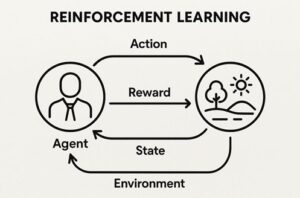
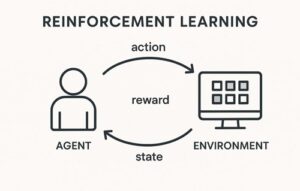
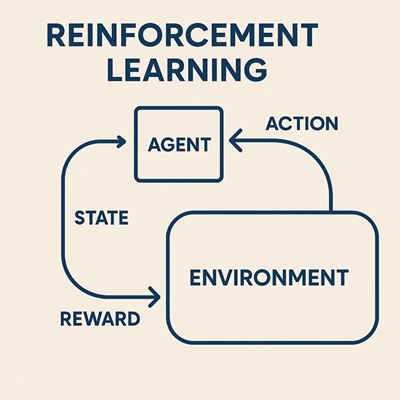
強化学習における割引率は、「将来に得られる報酬を、どの程度“今の価値として評価するか”」を決めるためのパラメータです。
エージェントは行動の結果としてすぐに報酬を得ることもあれば、かなり後になってから報酬を得ることもあります。
割引率は、そのような時間的に離れた報酬をどの程度重視するかを調整する役割を持っています。
割引率が小さい場合の意味
割引率を小さく設定すると、エージェントは 目先の報酬を強く重視 します。
この設定では、
- すぐに得られる報酬を優先する
- 将来の結果をあまり考慮しない
- 学習は比較的安定しやすく、早く進むことが多い
という特徴が現れます。
一方で、長期的には大きな利益につながる行動を見逃すという欠点も生じやすくなります。
割引率が大きい場合の意味
割引率を大きくすると、エージェントは 遠い将来の報酬まで含めて評価 するようになります。
この場合、
- 長期的な戦略を学習しやすい
- 一時的な損より、将来の大きな利益を優先する
- 計画性のある行動が生まれやすい
という利点があります。
ただしその反面、
- 将来の不確実性まで考慮するため、学習が不安定になりやすい
- 行動と結果の因果関係が分かりにくくなり、学習が遅くなることがある
というトレードオフも生まれます。
割引率が「どれくらい先まで効いているか」
割引率は、「どの程度先の未来まで影響が及ぶか」という 時間スケール を暗黙的に決めています。
割引率が大きいほど、
- エージェントはより長い時間軸で意思決定する
- 数十ステップ先、数百ステップ先の結果まで考慮する
割引率が小さいほど、
- 数ステップ先程度しか見ない
- その場その場の判断が中心になる
という性質が出ます。
そのため、割引率は環境の時間的な長さ(1エピソードがどれくらい続くか)に合わせて選ぶ必要があります。
「割引率が必要な理由」を正確に整理すると
割引率が使われる理由は、ひとつではありません。
継続タスクを扱いやすくするため
終わりのないタスクでは、将来の報酬をそのまま足し続けると、価値が無限に膨らんでしまう可能性があります。
割引率を入れることで、評価が有限になり、理論的にも実装的にも扱いやすくなります。
学習を安定させるため
将来の影響を適度に弱めることで、価値推定が暴走しにくくなり、学習が安定しやすくなります。
時間的な好みを表現するため
現実世界では「今もらえる報酬」と「1年後にもらえる報酬」は同じ価値とは感じません。
割引率は、こうした時間に対する価値観をモデルに組み込む役割も持っています。
割引率が1の場合についての正確な理解
割引率を最大値に設定すること自体は、必ずしも間違いではありません。
- 必ず終わるタスク(エピソードが有限)では、割引なしでも問題なく成立する場合が多い
- ゴールまでの全体像を完全に評価したい場合に使われることもある
一方で、
- 終わりのないタスク
- 報酬が継続的に発生する環境
では、割引なしの設定は目的そのものが不適切になりやすく、別の評価基準(平均的な報酬を最大化する考え方など)が使われることも多くなります。
実務での割引率の考え方
実際の応用では、割引率は「理論的に正しい値」ではなく、タスクに合った値を選ぶハイパーパラメータとして扱われます。
- 短いエピソード → やや大きめ
- 長期戦略が重要 → 大きめ
- ノイズが多い、即時性が重要 → 小さめ
- 学習が不安定 → 少し下げる
といった形で調整されることがほとんどです。
まとめ
- 割引率は「未来の報酬をどれだけ重視するか」を決める
- 小さい値は短期重視・安定しやすい
- 大きい値は長期重視・戦略的だが学習は難しい
- 割引率は収束性・安定性・時間スケールを同時に制御する
- タスクの性質に合わせて選ぶことが最重要
以上、強化学習の割引率についてでした。
最後までお読みいただき、ありがとうございました。