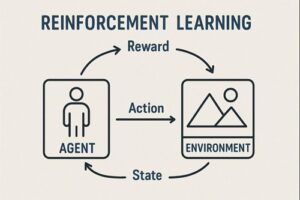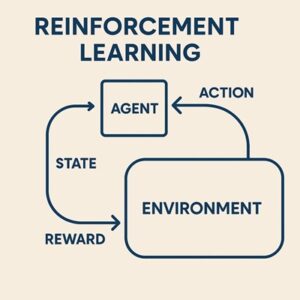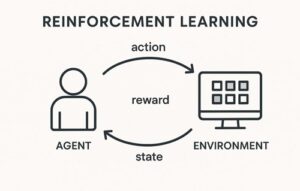

強化学習(Reinforcement Learning, RL)のアルゴリズムは非常に多く、分類の仕方を誤ると「何がどう違うのか」が分からなくなる分野です。
そのため本稿では、
- 強化学習アルゴリズムを分類するための軸
- 各カテゴリごとの代表的アルゴリズム
- それぞれの前提条件・得意領域・注意点
を明確にしながら整理します。
目次
強化学習アルゴリズムを整理するための基本軸
まず、以下の軸を明確にすると混乱が減ります。
- モデルベース / モデルフリー
- 価値ベース / 方策ベース / アクター・クリティック
- オンポリシー / オフポリシー
- 離散行動 / 連続行動
- 表形式 / 関数近似(ニューラルネット)
強化学習のアルゴリズムは、これらの組み合わせで位置づけられます。
計画法(モデル既知・古典的手法)
概要
- 環境の 状態遷移確率・報酬関数が既知
- 全状態を列挙できることが前提
- 「学習」というより 最適方策を解くための計画(Planning)
代表例
- Policy Iteration
- Value Iteration
注意点
これらは強化学習の理論的基礎として極めて重要ですが、
実環境で試行錯誤しながら学習するアルゴリズムとは前提が異なるため、
厳密には「学習アルゴリズム」というより「最適化手法」に近い位置づけです。
TD学習・表形式の制御アルゴリズム(モデルフリー)
概要
- 環境モデルを仮定しない
- 状態・行動価値を直接更新
- 多くの深層強化学習アルゴリズムの理論的土台
代表的アルゴリズム
- SARSA(オンポリシー)
- Q-learning(オフポリシー)
- Expected SARSA
補足
- SARSAは「実際に使っている方策」に従って更新するためオンポリシー
- Q-learningは「最適行動」を仮定して更新するためオフポリシー
- Expected SARSAは
- どの方策で期待値を取るか
- どの方策でデータを収集するか
によって性質が変わるため、単純にオン/オフと断定しない方が正確
価値ベース強化学習(Value-Based Methods)
基本思想
- 「この状態でこの行動を取ると、将来どれだけ報酬が得られるか」
- Q関数を学習し、最大値を取る行動を選択
- 方策は価値関数から間接的に決まる
深層強化学習の代表
- DQN(Deep Q-Network)
- Double DQN
- Dueling DQN
- Prioritized Experience Replay
- n-step DQN
- Distributional DQN
- Rainbow DQN(複数改良の統合)
特徴
- 離散行動に強い
- 実装は比較的分かりやすい
- 連続行動空間では扱いにくい(離散化が必要)
方策ベース強化学習(Policy-Based Methods)
基本思想
- 方策(π)そのものを直接最適化
- 確率的ポリシーを扱える
代表的アルゴリズム
- REINFORCE
- Policy Gradient
- TRPO
- PPO(Proximal Policy Optimization)
特徴
- 連続行動を自然に扱える
- 方策が安定しやすい
- サンプル効率が低くなりやすい
- PPOは現在でも研究・実務で非常に広く使われるオンポリシー手法
アクター・クリティック(Actor-Critic)
基本思想
- Actor:行動を決定する(方策)
- Critic:その行動の価値を評価
- 価値ベースと方策ベースの折衷
代表的アルゴリズム
オンポリシー系
- A2C
- A3C
オフポリシー系(連続制御の主流)
- DDPG
- TD3
- SAC(Soft Actor-Critic)
特徴
- 高性能・高安定
- 実装はやや複雑
- 連続制御問題では事実上の主流カテゴリ
モデルベース強化学習(Model-Based RL)
概要
- 状態遷移モデルや報酬モデルを利用
- サンプル効率が高いのが最大の利点
分類すると理解しやすい
(A) モデル既知で計画
- Value Iteration
- Policy Iteration
(B) モデルを学習して利用
- Dyna-Q
- MBPO(Model-Based Policy Optimization)
- Dreamer 系
(C) 生成器を使った探索
- MCTS(Monte Carlo Tree Search)
注意点
- モデル誤差が性能劣化に直結する
- 高次元環境では設計が難しい
オンポリシーとオフポリシーの整理
| 区分 | 特徴 | 代表例 |
|---|---|---|
| オンポリシー | 現在の方策で集めたデータのみ使用 | SARSA, PPO, A2C |
| オフポリシー | 過去データや別方策のデータも利用 | Q-learning, DQN, DDPG, TD3, SAC |
※ 「オフポリシーが常に優れている」というわけではなく、
安定性・理論保証・用途によってオンポリシーが選ばれる場面も多く存在します。
代表アルゴリズムの用途別整理
| アルゴリズム | 行動空間 | 特徴 | 主な用途 |
|---|---|---|---|
| Q-learning | 離散 | 理論の基礎 | 学習・教材 |
| DQN | 離散 | Deep RL入門 | ゲーム |
| PPO | 離散/連続 | 安定・汎用 | ロボ・シミュレーション |
| DDPG | 連続 | 高性能だが不安定 | 制御 |
| TD3 | 連続 | DDPG改良 | 連続制御 |
| SAC | 連続中心 | 安定・高性能 | 実務・研究 |
まとめ
- 強化学習は 分類軸を意識しないと誤解しやすい
- DPやMCTSは「学習アルゴリズム」とは前提が異なる
- 現代の主流は
モデルフリー × アクター・クリティック × 深層学習 - 実務・研究の入口としては
PPO(安定)、SAC(連続制御)が定番
以上、強化学習のアルゴリズムの一覧についてでした。
最後までお読みいただき、ありがとうございました。