
大規模言語モデル(LLM)における強化学習(Reinforcement Learning, RL)は、単に文章を自然に生成するだけでなく、人間の意図・好み・安全基準に沿った振る舞いを実現するための重要な学習工程です。
特に近年は、RLHF(Reinforcement Learning from Human Feedback:人間のフィードバックを用いた強化学習)を中心に、LLMの実用性と信頼性を高める技術として発展してきました。
強化学習とは何か(LLM文脈での定義)
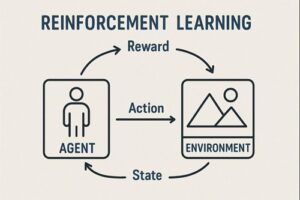
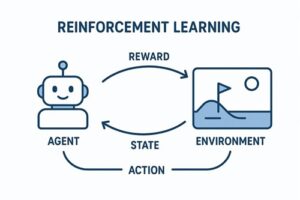
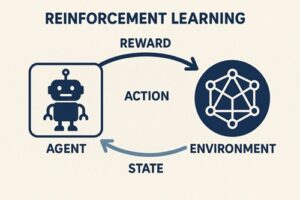
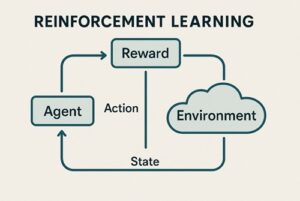
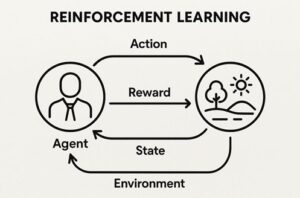
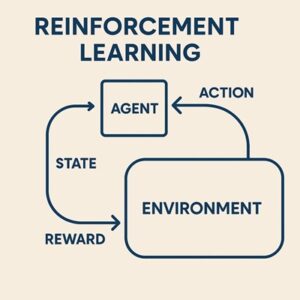
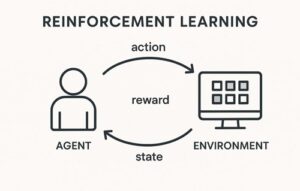
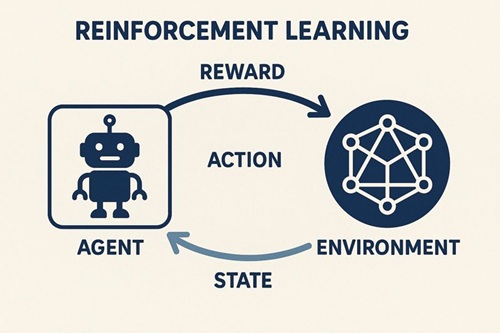
一般的な強化学習では、
- 行動主体(エージェント)
- 状態
- 行動
- 報酬
を通じて、「将来の報酬を最大化する行動方針(ポリシー)」を学習します。
これをLLMに当てはめると、以下のように整理できます。
| 強化学習の要素 | LLMにおける意味 |
|---|---|
| エージェント | 言語モデル |
| 状態 | これまでの入力や文脈(プロンプト+生成途中のトークン列) |
| 行動 | 次に生成するトークンの選択 |
| 報酬 | 出力がどれだけ望ましいかを示す評価値 |
| ポリシー | トークンを選択する確率分布 |
LLMでは、「文章全体の良し悪し」が評価される一方で、実際の行動はトークン単位で行われるため、強化学習としては非常に難易度の高い問題設定になります。
なぜLLMに強化学習が必要なのか
事前学習だけでは不十分な理由
LLMはまず、大量のテキストデータを用いて「次の単語(トークン)を予測する」自己教師あり学習を行います。
この段階でモデルは、
- 文法的に自然な文章
- 統計的にもっともらしい表現
を生成できるようになりますが、以下の問題が残ります。
- 指示を正確に守らない
- 回答が冗長、または的外れ
- 人間にとって不親切、危険、不適切な表現を含む可能性
つまり、
「言語として自然であること」と
「人間にとって良い回答であること」
は一致しない
というギャップが生じます。
強化学習の役割
強化学習はこのギャップを埋めるために使われます。
- 人間(または評価器)が回答の良し悪しを評価
- その評価を数値(報酬)としてモデルに与える
- 報酬が高くなるよう、出力の傾向を調整する
これにより、LLMは単なる言語モデルから、「人間の期待に沿って振る舞う対話モデル」へと変化します。
RLHF(人間のフィードバックを用いた強化学習)の基本構造
LLMの強化学習は、いきなりRLを行うのではなく、段階的に進められるのが一般的です。
典型的な構成は次の3ステップです。
教師あり微調整(SFT: Supervised Fine-Tuning)
- 人間が作成した「望ましい回答例」を用意
- 入力と理想的な出力のペアを学習
この段階の目的は、最低限、指示に従って自然な会話ができるモデルを作ることです。
報酬モデル(Reward Model)の学習
- 同じ質問に対して複数の回答を用意
- 人間が「どちらがより良いか」を比較・ランキング
- その判断を学習し、「文章の良さ」を数値で返すモデルを作る
この報酬モデルは、人間の好みを近似的に再現する評価器として機能します。
強化学習による最適化
- LLMが回答を生成
- 報酬モデルがスコアを付与
- スコアが高くなるようLLMの出力分布を更新
この工程で、初めて本格的な強化学習アルゴリズムが使われます。
※近年では、②や③を簡略化・省略する手法(DPOなど)も広く使われています。
強化学習アルゴリズムとPPOの位置づけ
PPO(Proximal Policy Optimization)
RLHFの文脈で長く使われてきた代表的な手法が PPO です。
PPOの特徴は、
- ポリシー(出力分布)を急激に変えすぎない
- 学習が比較的安定しやすい
- 大規模モデルでも破綻しにくい
という点にあります。
LLMでは、出力分布が大きく変わりすぎると、
- 意味不明な文章になる
- 文法や一貫性が崩れる
といった問題が起きやすいため、「少しずつ改善する」制約が非常に重要です。
近年の動向
ただし現在では、
- DPO(Direct Preference Optimization)
- IPO、SLiC などの選好最適化手法
といった、PPOを使わずに人間の好みを直接最適化する方法も一般化しています。
PPOは依然として重要な基礎技術ですが、唯一の選択肢ではありません。
LLM強化学習の目的関数の考え方(直感的説明)
LLMの強化学習では、単に「報酬を最大化」するだけではありません。
実際には、
- 報酬モデルによる評価を高めたい
- しかし、元の言語モデルから逸脱しすぎると品質が崩れる
というトレードオフがあります。
そのため多くの場合、
- 報酬を高める項
- 参照モデルとのズレ(KL距離)を抑える罰則項
を組み合わせた最適化が行われます。
直感的には、
「人間にとって良い回答を増やしつつ、
言語としての自然さは壊さない」
という調整です。
強化学習によって得られる効果
指示追従性の向上
- ユーザーの要求を正確に満たす
- 文体や形式を指示通りに調整できる
安全性・信頼性の向上
- 危険・不適切な回答の抑制
- 拒否や注意喚起を適切に行う振る舞い
※実運用では、これらは強化学習単体ではなく、
データ設計・ルール・推論時制御と組み合わせて実現されます。
実用性の向上
- 冗長すぎない説明
- 構造化された回答
- 実務でそのまま使える文章品質
課題と限界
報酬ハッキング
モデルが「本質的に良い回答」ではなく、評価器(報酬モデル)の癖を突いた回答を生成してしまう問題。
評価コストとバイアス
- 人間評価は高コスト
- 評価基準の一貫性を保つのが難しい
多様性の低下
- 無難で平均的な回答に収束しやすい
- 創造性が下がる場合がある
RLHF以外の発展的アプローチ
- RLAIF:人間の代わりにAIが評価を行う
- DPO:報酬モデルやPPOを使わず、好みデータから直接最適化
- Constitutional AI:原則(ルール)に基づき、AIが自己批評・自己修正を行う枠組み
これらは、スケール性・安定性・コスト削減を目的として研究・実用が進んでいます。
まとめ
LLMにおける強化学習は、
- 事前学習だけでは得られない「人間らしさ」
- 指示追従性・安全性・実用性
を後から付与するための中核技術です。
現在のLLMは、教師あり学習・強化学習・評価設計・推論時制御を組み合わせた総合システムとして成立しており、強化学習はその中でも極めて重要な役割を担っています。
以上、LLMにおける強化学習についてでした。
最後までお読みいただき、ありがとうございました。