
目次
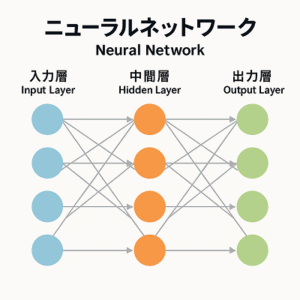
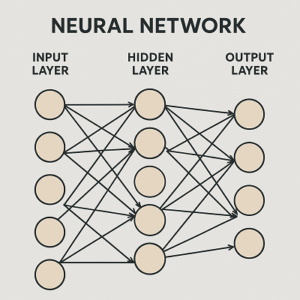
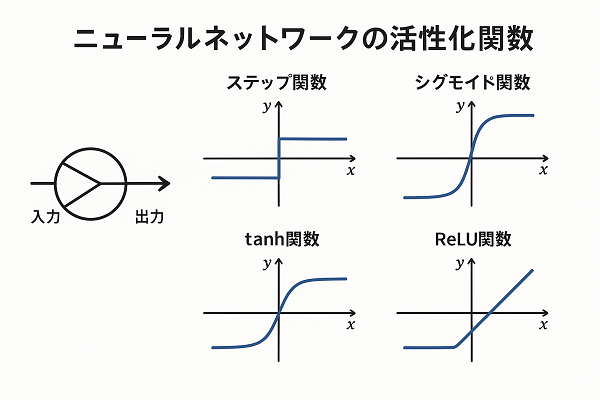
活性化関数とは
活性化関数(activation function)は、ニューラルネットワークに非線形性を与えるための関数です。
各ニューロンに入力される値(重み付き和 + バイアス)を、非線形に変換することで、単純な線形結合だけでは表現できない複雑な関係性を学習可能にします。
もし活性化関数を使わなければ、どれほど多層構造にしてもネットワーク全体は線形変換の組み合わせにすぎず、深層学習の真価を発揮することはできません。
活性化関数の主な役割
活性化関数は、以下の3つの重要な役割を担います。
- 非線形性の導入
→ モデルに複雑な表現能力を与える。 - 勾配の安定化
→ 学習中に勾配が消失(vanishing gradient)または爆発(exploding gradient)しないよう制御する。 - 出力スケールの制御
→ 出力値を一定範囲(例:0〜1, −1〜1)に抑えることで、学習の安定性を高める。
主な活性化関数と特徴
Sigmoid 関数
- 出力範囲: (0, 1)
- 特徴:古典的な関数で、出力を確率として解釈できる。
- 利点:確率的出力が求められるタスクに適する。
- 欠点:入力が大きいと勾配がほぼゼロになり、勾配消失が発生。
主な用途:2値分類タスクの出力層(例:スパム判定)
tanh 関数(双曲線正接関数)
- 出力範囲: (−1, 1)
- 特徴:Sigmoidを0中心にシフトした形。
- 利点:出力平均が0付近にあり、学習が比較的安定。
- 欠点:依然として勾配消失が起きやすい。
主な用途:RNN(再帰型ニューラルネットワーク)の中間層など。
ReLU(Rectified Linear Unit)
- 出力範囲: [0, ∞)
- 特徴:現在最も一般的な活性化関数。
- 利点:
- 勾配消失を大幅に緩和。
- 計算コストが低く高速。
- 欠点:
- 負の入力に対して常に0となり、「死んだReLU問題(Dead ReLU)」が起こることがある。
主な用途:CNN・DNNの中間層全般。
Leaky ReLU(リーキーReLU)
- 出力範囲: (−∞, ∞)
- 特徴:ReLUの改良版。負の入力でも微小な勾配を残す。
- 利点:「死んだニューロン」問題を軽減。
- 欠点:ハイパーパラメータαの調整が必要。
PReLU(Parametric ReLU)
Leaky ReLU のαを学習可能なパラメータとして扱う関数。
ネットワーク自身が最適な傾きを学習できる。
ELU(Exponential Linear Unit)
- 出力範囲: (−α, ∞)
- 特徴:負側で滑らかな変化を持ち、平均出力を0に近づける。
- 利点:学習の収束が速く、勾配消失にも強い。
- 欠点:指数関数演算が必要なため、やや計算コストが高い。
Swish(Google提案)
- 出力範囲: 約 (−0.2785, ∞)
- 特徴:入力とSigmoidを掛け合わせた「自己ゲート型」関数。
- 利点:ReLUより滑らかで、高精度モデルで好成績。
- 欠点:やや計算が重い。
GELU(Gaussian Error Linear Unit)
- 出力範囲: 約 (−0.17, ∞)
- 特徴:確率的に入力をゲートする滑らかな関数。
- 利点:自然言語処理において非常に有効。
- 用途:BERT・GPTなどTransformer系モデルの標準活性化関数。
活性化関数の比較表(改訂版)
| 関数名 | 出力範囲 | 非線形性 | 勾配消失 | 主な用途 |
|---|---|---|---|---|
| Sigmoid | (0, 1) | 弱い | あり | 出力層(2値分類) |
| tanh | (−1, 1) | 中程度 | あり | RNNなど |
| ReLU | [0, ∞) | 強い | 少ない | CNN, DNN一般 |
| Leaky ReLU | (−∞, ∞) | 強い | 少ない | ReLU改良型 |
| PReLU | (−∞, ∞) | 強い | 少ない | 高精度モデル |
| ELU | (−α, ∞) | 強い | 少ない | 高速学習モデル |
| Swish | (約 −0.2785, ∞) | 滑らか | 少ない | 高精度モデル |
| GELU | (約 −0.17, ∞) | 滑らか | 少ない | Transformer系 |
活性化関数の選択ガイド
- 画像認識・一般構造モデル → ReLU / Leaky ReLU / PReLU
- 自然言語処理(Transformer系) → GELU
- 出力層の定番
- 2値分類 → Sigmoid
- 多クラス分類 → Softmax
- 回帰問題 → 恒等関数 (f(x)=x)
実務的な観点から
ウェブマーケティング分野でも、AI広告最適化やレコメンドエンジン、顧客離脱予測などでディープラーニングが活用されています。
これらの内部では、活性化関数が「モデルの表現力と安定性」を決定する重要な要素となっています。
たとえば
- CTR予測モデル → Sigmoid(確率出力)
- ブランドロゴ認識 → ReLU(画像特徴抽出)
- テキスト感情分析 → GELU(Transformerベース)
まとめ
活性化関数は、ニューラルネットワークに「非線形な知能」を与える中核的要素です。
選択次第で、学習の速度・安定性・精度が大きく変化します。
- 古典的:Sigmoid / tanh
- 現代標準:ReLU / Leaky ReLU / PReLU
- 高精度モデル:Swish / GELU
特別な理由がない限りReLU(画像系)またはGELU(NLP系)を採用するのが最適解といえるでしょう。
以上、ニューラルネットワークの活性化関数についてでした。
最後までお読みいただき、ありがとうございました。