
機械学習の文脈でよく登場する「強化学習(Reinforcement Learning)」 と「ファインチューニング(Fine-tuning)」。
どちらも「AIを賢くする方法」ではありますが、学習の考え方・必要なデータ・得意分野は本質的に異なります。
本記事では、定義の厳密さを保ちながら、実務でも誤解なく使える形で両者の違いを整理します。
結論を先に:最大の違いは「教え方」
| 観点 | ファインチューニング | 強化学習 |
|---|---|---|
| 学習の基本 | 正解例を与えて調整 | 試行錯誤で報酬を最大化 |
| 教師データ | 多くの場合は必要(SFT) | 正解ラベルは不要 |
| フィードバック | 正解/不正解 | 報酬(良し悪し) |
| 得意分野 | 業務特化・安定性 | 最適化・戦略学習 |
| 実装難易度 | 比較的低い | 高い |
ファインチューニングとは何か
定義
ファインチューニング(fine-tuning)とは、事前学習済みのモデルを、特定の目的・タスク・ドメインに適応させるために追加学習を行うことです。
現在のAI開発では、
事前学習 → ファインチューニング
という構成がほぼ標準になっています。
教師ありファインチューニング(SFT)が主流
実務で使われるファインチューニングの多くは教師ありファインチューニング(Supervised Fine-Tuning:SFT)です。
例(文章分類)
入力:この商品は本当に使いやすい
正解:ポジティブ
モデルは
- 出力が正解とズレた分だけ誤差を計算し
- パラメータを微調整する
これを繰り返すことで、特定用途に最適化されます。
「正解データは必須」ではない点に注意
一般的にはSFTが主流ですが、厳密には以下もファインチューニングと呼ばれる場合があります。
- 特定ドメインのテキストを追加学習(ラベルなし)
- 自己教師あり的な追加事前学習
- ドメイン適応(Domain Adaptation)
そのため、正確には
ファインチューニングは「必ず教師あり」ではないが、
実務では教師あり(SFT)が圧倒的に多い
と理解するのが適切です。
ファインチューニングの特徴まとめ
メリット
- 学習が安定しやすい
- 少量データでも効果が出やすい
- 結果の再現性が高い
デメリット
- 正解データ作成コスト
- 想定外ケースへの柔軟性は限定的
強化学習とは何か
定義
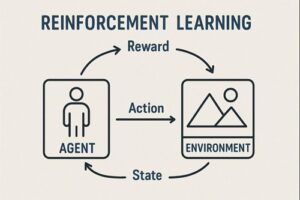
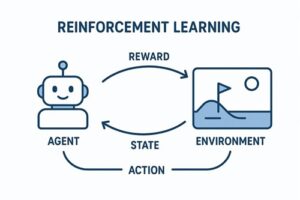
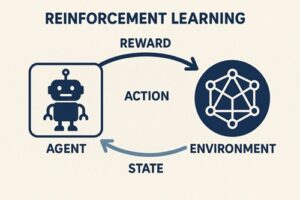
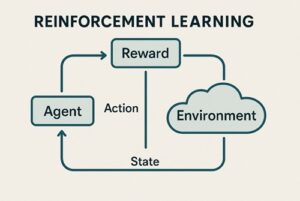
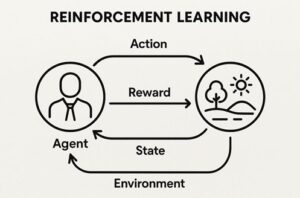
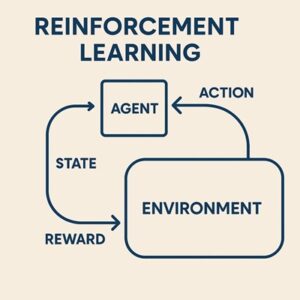
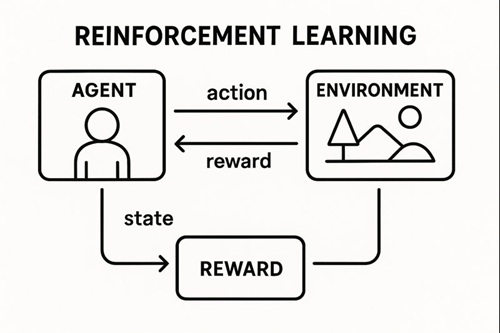
強化学習(Reinforcement Learning)とは、エージェント(AI)が環境と相互作用しながら、報酬を最大化する行動戦略(方策)を学習する枠組みです。
最大の特徴は、
「正解行動」を直接教えない
点にあります。
強化学習の3要素
| 要素 | 内容 |
|---|---|
| エージェント | 行動主体(AI) |
| 環境 | 行動の結果が返る世界 |
| 報酬 | 行動の良し悪しを示すスカラー値 |
学習の基本サイクル
- 状態を観測
- 行動を選択
- 環境が変化
- 報酬を受け取る
- より良い行動を学習
この試行錯誤のループが強化学習の本質です。
「正解を教えない」はどういう意味か
強化学習では、
- 「この行動が正解」とは教えない
- 「良かったか/悪かったか」だけが返る
ただし実際には、
- 報酬設計(reward shaping)
- 人間のデモ(模倣学習)
- 人間の好みを使った評価(RLHF)
など、学習を誘導する仕組みは多く使われます。
試行回数についての正確な理解
よく「強化学習は何百万回も試す」と言われますが、
- これは Deep RL + シミュレーション環境 で多い傾向
- オフラインRLや制約付き環境では必ずしもそうではない
という点は補足が必要です。
ファインチューニングと強化学習の思想的な違い
教え方の違い
- ファインチューニング
→「この入力にはこの出力が望ましい」 - 強化学習
→「今の行動はどれくらい良かったか」
人間の学習に例えると
| 人間 | AI |
|---|---|
| 解答集で勉強 | ファインチューニング |
| 失敗しながら上達 | 強化学習 |
ChatGPTと両者の関係(誤解されやすい点)
ChatGPTのような会話モデルは、
- 大規模データでの事前学習
- 教師ありファインチューニング(SFT)
- RLHF(人間のフィードバックを使った強化学習)
という流れをベースにしています。
重要なのは
- 知識・文法・基礎能力 → ファインチューニング
- 振る舞い・安全性・好ましさ → 強化学習
という役割分担です。
※ 実際のプロダクトでは、これに安全フィルタや追加調整が加わります。
実務での使い分け指針
ファインチューニングが向いているケース
- 正解が定義できる
- 業務が定型的
- 安定した出力が必要
例
- SEO記事生成
- 問い合わせ分類
- 広告文テンプレ生成
強化学習が向いているケース
- 正解が一意でない
- 長期的な最適化が必要
- 試行錯誤が本質
例
- 広告入札最適化
- レコメンドCTR最大化
- ゲーム・シミュレーションAI
まとめ
- ファインチューニング
- 事前学習モデルを用途特化
- 多くは教師あり(SFT)
- 安定性・実務適性が高い
- 強化学習
- 報酬を通じた試行錯誤
- 正解行動は直接教えない
- 最適化・戦略問題に強い
以上、強化学習とファインチューニングの違いについてでした。
最後までお読みいただき、ありがとうございました。