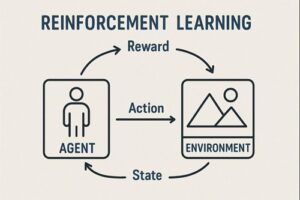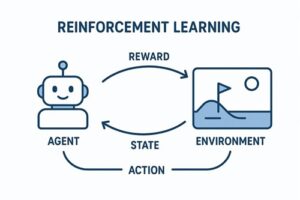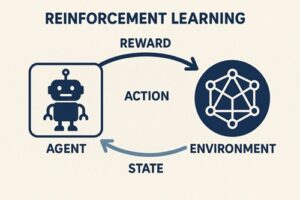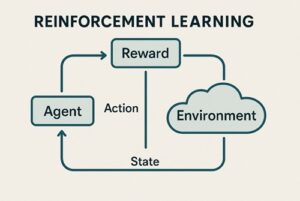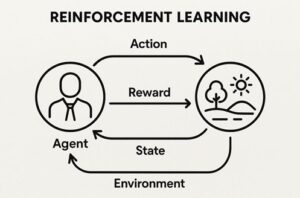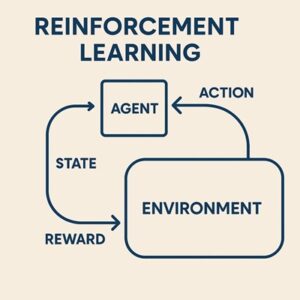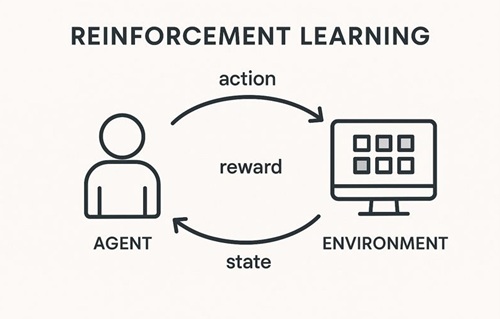

強化学習におけるエージェントとは、環境と継続的にやり取りをしながら、将来的に得られる報酬の合計ができるだけ大きくなるように行動を学習する意思決定主体のことです。
エージェントは、あらかじめ「正解となる行動」を教えられるわけではありません。
その代わり、行動の結果として環境から返ってくる報酬を手がかりに、「どのような行動が長期的に望ましいか」を試行錯誤しながら学びます。
エージェントと環境の基本的な関係
強化学習では、次のようなやり取りが繰り返されます。
- 環境が現在の状況(状態)をエージェントに提示する
- エージェントがその状況に基づいて行動を選択する
- 環境が行動の結果として
- 次の状況
- 評価値としての報酬
を返す
- エージェントはこの結果を記録し、行動の選び方を少しずつ調整する
このループを通じて、エージェントは「目先の得」ではなく、将来も含めたトータルの成果を最大化する行動戦略を身につけていきます。
エージェントを構成する主要な考え方
方策(ポリシー)
方策とは、「ある状況で、どの行動を取るか」を決めるためのルールです。
- 常に同じ行動を選ぶ決定的なものもあれば
- 状況に応じて、確率的に行動を選ぶものもあります
実用的な強化学習では、この方策をニューラルネットワークなどで表現し、経験に応じて更新します。
価値(バリュー)
価値とは、「その状況、あるいはその行動が、将来的にどれだけ良い結果につながりそうか」を数値として表した概念です。
- 状況そのものの良さを表すもの
- ある状況で特定の行動を取ることの良さを表すもの
があります。
重要なのは、これらの価値は常に“どの方策に従って行動するか”を前提に定義されるという点です。
価値は絶対的なものではなく、行動の取り方が変われば評価も変わります。
報酬
報酬は、環境がエージェントの行動に対して返す評価値です。
多くの強化学習では、報酬は単一の数値として与えられます。
ただし実務や研究では、複数の目的(利益と安全性など)を同時に考えるため、複数の評価指標を扱うこともあります。
報酬の設計次第で、エージェントの学習結果は大きく変わるため、報酬設計は強化学習で最も重要な要素の一つです。
割引の考え方
将来の報酬をどれくらい重視するかを決める考え方があります。
- 将来を重く評価すると、長期的に有利な行動を学びやすくなる
- 目先を重視すると、短期的な成果を優先する行動になりやすい
このバランスの取り方が、エージェントの性格を大きく左右します。
エージェントの学習アプローチの違い
モデルフリー型エージェント
環境の内部構造を明示的に理解しようとせず、経験の積み重ねだけで学習するタイプです。
- 実装が比較的シンプル
- 多くの実用システムで使われている
- 学習には試行回数が多く必要になることがある
Q学習やDQN、方策勾配法などがこの系統に含まれます。
モデルベース型エージェント
環境がどのように変化するか(行動すると次にどうなるか)を予測するモデルを持ち、それを使って先を見越した判断を行うタイプです。
- 学習効率が高くなりやすい
- 設計や実装は難しい
- 現実世界の複雑な環境では不安定になることもある
代表的なエージェントの考え方
価値ベースのエージェント
行動の良し悪しを「価値」として評価し、その評価が最も高くなる行動を選ぶタイプです。
- 離散的な行動空間と相性が良い
- 行動の選択が直感的
- 探索の工夫が重要
Q学習やDQNが代表例です。
方策ベース/Actor-Critic系エージェント
行動の選び方そのものを直接改善していくタイプです。
- 確率的な行動を自然に扱える
- 連続的な操作(ロボット制御など)に向いている
- 学習の安定化のために価値評価を併用することが多い
PPO や A2C / A3C などが代表例です。
エージェントが必ず直面する本質的な問題
探索と活用のバランス
- 新しい行動を試さなければ、より良い戦略は見つからない
- しかし試しすぎると、得られる成果が安定しない
このバランスをどう取るかは、すべての強化学習エージェントに共通する課題です。
想定外の学習結果
報酬の与え方が不適切だと、エージェントは人間の意図とは異なる行動を合理的に学習してしまうことがあります。
これは「エージェントが間違っている」のではなく、「評価基準の設計が不十分」な場合に起こります。
まとめ
強化学習のエージェントとは、
- 環境との相互作用を通じて
- 行動の結果として得られる評価を蓄積し
- 将来を含めた成果が最大になるように
- 行動の選び方(方策)を改善し続ける存在
です。
以上、強化学習のエージェントについてでした。
最後までお読みいただき、ありがとうございました。