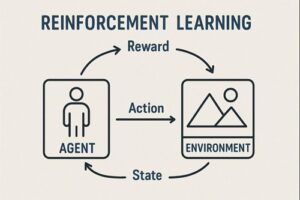

強化学習(Reinforcement Learning)において、報酬の設計はアルゴリズム選択と同じくらい、あるいはそれ以上に重要です。
学習が思うように進まない場合、その原因が報酬設計にあるケースは非常に多く見られます。
本記事では、報酬設計の基本的な考え方から、実務で失敗しにくい判断軸、そしてよくある落とし穴までを、数式を使わずに体系的に解説します。
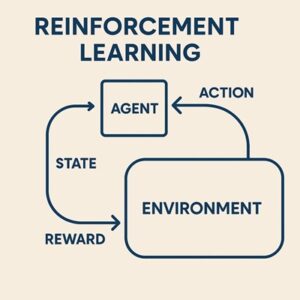
強化学習における報酬の役割
強化学習エージェントは、「人間にとって正しい行動」や「常識」を理解しているわけではありません。
エージェントが最終的に最適化するのは、得られる報酬の合計をできるだけ大きくすることだけです。
そのため、
- 人間が意図した目標
- 報酬を最大化した結果として選ばれる行動
この二つが一致していないと、エージェントは正しく学習しながら、望ましくない行動を取ることになります。
報酬設計とは、エージェントが「何を良い行動だと解釈するか」を定義する作業だと言えます。
報酬設計の代表的なパターン
スパース報酬(Sparse Reward)
スパース報酬とは、ゴールを達成したときだけ報酬を与える設計です。
途中の行動にはほとんど報酬を与えません。
特徴
- 目標を直接表現できるため、行動の歪みが起きにくい
- 探索が難しく、学習に時間がかかりやすい
向いているケース
- 状態や行動の選択肢が比較的少ない
- 試行回数を多く確保できるシミュレーション環境
デンス報酬(Dense Reward)
デンス報酬では、各ステップで進捗や状態の良さに応じた報酬を与えます。
特徴
- 学習初期から「どちらに進めばよいか」が分かりやすい
- 設計を誤ると、本来の目的とは異なる行動が最適化される
向いているケース
- ロボット制御や連続制御タスク
- 実環境で試行回数が限られている場合
報酬設計における実践的な考え方
目的報酬と進捗報酬を使い分ける
報酬設計では、
- ゴール達成そのものを評価する「目的報酬」
- ゴールに近づく過程を評価する「進捗報酬」
のどちらを採用するか、あるいは組み合わせるかを意識する必要があります。
進捗報酬は学習を加速させますが、使い方を誤ると、エージェントが「進捗を装う行動」だけを繰り返すことがあります。
状態そのものより「変化」を評価する場合もある
現在の状態が良いかどうかではなく、「前の状態から改善したかどうか」に報酬を与えると、学習が安定することがあります。
ただしこの方法は、
- 環境にノイズがある場合
- 改善と悪化を細かく繰り返せる場合
には、意図しない報酬獲得行動を生みやすくなるため注意が必要です。
行動ではなく結果を評価する
特定の行動に直接報酬を与えると、行動そのものが目的化してしまい、環境が少し変わっただけで性能が崩れることがあります。
より汎用的な学習を目指すなら、行動の結果として生じた状態や成果を評価する設計が適しています。
ペナルティは「目的」と「制約」を分けて考える
負の報酬(ペナルティ)は、行動を強く抑制する効果がありますが、使いすぎると探索を妨げる原因になります。
一方で、
- 安全違反
- 物理的な破損
- ルールや法令違反
といった「絶対に避けたい事象」は、軽いペナルティではなく、明確な失敗として扱う方が適切です。
報酬ハックと局所最適の問題
報酬ハック
報酬設計が人間の意図を完全に表現できていないと、エージェントは想定外の方法で報酬を稼ごうとします。
これはエージェントの誤動作ではなく、与えられた報酬を忠実に最大化した結果です。
対策としては、
- 制約条件を明確にする
- 学習中の行動を観察し、段階的に修正する
- 報酬を過度に単純化しない
といった地道な調整が重要になります。
局所最適への収束
小さな報酬を安定して得られる行動に固執し、本来のゴールに向かわなくなるケースは珍しくありません。
この問題は、報酬設計だけでなく、
- 割引の考え方
- 探索戦略
- 学習の安定性
といった要素とも密接に関係しています。
進捗報酬を使う際の重要な注意点
進捗を評価する報酬を追加すると、学習は速くなりますが、本来解きたい問題とは別の問題を解いてしまう可能性があります。
そのため、進捗報酬は「最終的に望む行動を変えていないか」という視点で慎重に設計する必要があります。
実務では、
- 最初はゴール重視の単純な報酬から始める
- 必要に応じて進捗評価を少しずつ追加する
という段階的なアプローチが有効です。
アルゴリズムと報酬設計の関係
Q-learning / DQN 系
- 報酬の大きさやばらつきの影響を受けやすい
- 発散や不安定さは、報酬設計だけでなく学習手法全体の組み合わせによって起きる
Policy Gradient / PPO 系
- 報酬の設計が行動の傾向に直接反映されやすい
- 報酬の調整は、正規化や探索の設定と合わせて行う必要がある
実務で失敗しにくい設計プロセス
- 何を達成したいのかを明確に言語化する
- ゴールを観測可能な要素に分解する
- まずはシンプルな報酬で学習させる
- 行動を観察し、問題があれば修正する
- 必要に応じて段階的に報酬を追加する
報酬設計は一度で完成するものではなく、試行錯誤を前提とした設計作業です。
まとめ
- 強化学習は報酬を最大化する枠組みで動作する
- 報酬設計は人間の意図を行動に翻訳する作業
- スパースとデンスには明確なトレードオフがある
- 進捗報酬は便利だが、使い方を誤ると目的が変わる
- 観察と修正を繰り返すことが成功への近道
以上、強化学習の報酬の決め方についてでした。
最後までお読みいただき、ありがとうございました。