
強化学習(Reinforcement Learning:RL)は、ロボットに対して「環境と相互作用しながら自ら行動を改善する能力」を与えるための重要な機械学習手法です。
従来のロボット制御では、人間があらかじめ詳細なルールや数式モデルを設計することが前提とされてきましたが、強化学習では試行錯誤を通じて最適な行動方策を学習する点が大きな特徴となっています。
本稿では、強化学習の基本構造を整理したうえで、ロボット分野との関係性、代表的な応用例、そして実用上の課題について解説します。
ロボット視点で理解する強化学習の基本構造
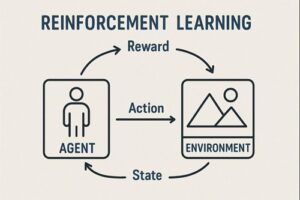
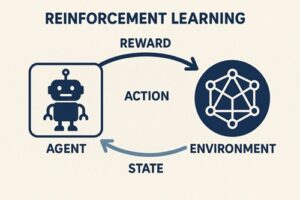
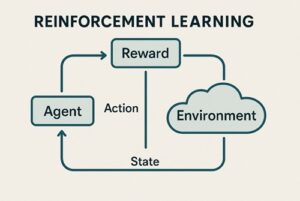
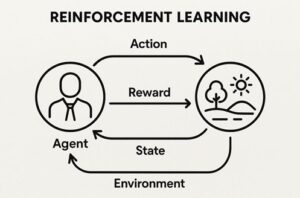
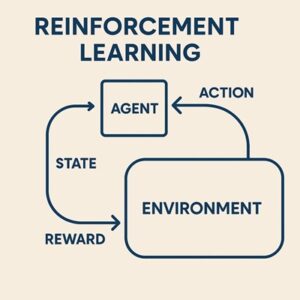
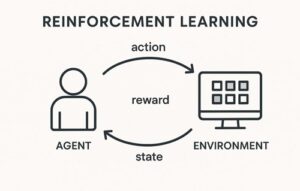
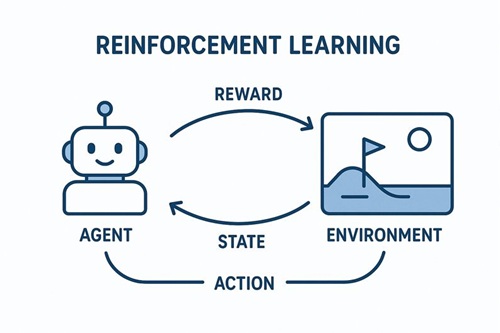
強化学習は、主に次の4つの要素から構成されています。
- エージェント:意思決定を行う主体であり、ロボットそのものを指します
- 環境:ロボットが行動する世界で、実世界またはシミュレーション環境です
- 行動:ロボットが選択する操作で、移動、関節制御、把持動作などが該当します
- 報酬:行動の結果に対する評価信号です
ロボットは「行動 → 環境の変化 → 観測 → 報酬」というサイクルを繰り返しながら、長期的な報酬を最大化する行動方策(ポリシー)を学習していきます。
この枠組みは、正解行動を事前に明確に定義しにくいロボットタスクと高い親和性を持っています。
なぜロボット分野で強化学習が注目されているのか
明示的なルール設計の限界
実世界で動作するロボットは、摩擦や剛性の変動、センサー誤差、外乱など、多くの不確実性を含んでいます。
これらをすべて数式や条件分岐として正確に記述することは現実的ではありません。
強化学習は、こうした不確実性を環境との相互作用から学習する問題として扱えるため、従来手法では対応が難しかった状況への適応が期待されています。
観測に基づく評価が可能である点
ロボットは、位置や姿勢、接触状態、作業の成否などをセンサーを通じて観測できます。
このため、行動結果に基づく評価信号を定義することが可能です。
ただし、評価基準(報酬)の設計自体は容易ではなく、慎重な設計が求められます。
ロボット分野における強化学習の代表的な応用例
移動・歩行制御(ロコモーション)
二足歩行ロボットや四足歩行ロボットでは、安定した歩行や効率的な移動方法をあらかじめプログラムすることが困難です。
強化学習を用いることで、「転倒しない」「前進する」「エネルギー消費を抑える」といった評価基準のみを与え、歩行パターンを自律的に学習させる研究が進められています。
マニピュレーション(把持・操作)
ロボットアームによる物体の把持や操作では、対象物の形状や位置が変化する状況に対応する必要があります。
強化学習を活用することで、多少の位置ずれや外乱があっても成功率を維持できる柔軟な動作を学習させることが可能になります。
自律移動・ナビゲーション
障害物回避、経路選択、混雑回避といったタスクも、強化学習では報酬最大化問題として統合的に扱うことができます。
そのため、移動ロボットやサービスロボット分野での応用が検討されています。
シミュレーションと実ロボットの関係(Sim2Real)
実ロボット上で直接強化学習を行う場合、学習時間の長さや機体の損傷リスク、コストの問題が生じます。
そのため、多くの研究や開発では、シミュレーション環境で学習した方策を実ロボットへ転移する「Sim2Real」の手法が採用されています。
ただし、シミュレーションと現実の物理特性には差が存在し、この差が性能低下の原因となることがあります。
これを緩和する手法として、物理パラメータやノイズをランダムに変化させるドメインランダム化が用いられていますが、完全な解決策ではなく、現在も研究が続けられています。
ロボット制御における強化学習アルゴリズムの位置づけ
- Q-learning や DQN
基本的に離散的な行動空間を前提としているため、ロボットでは行動を離散化した場合や限定的な用途で利用されることが多いです。 - Actor-Critic 系手法(PPO、SAC など)
連続行動空間を直接扱えるため、関節角度やトルク制御を必要とするロボットに適しています。研究や実験用途では代表的な手法として広く用いられています。 - モデルベース強化学習
環境のダイナミクスモデルを利用して計画や学習を行う手法群であり、MPC(モデル予測制御)と組み合わせて使われる場合もあります。ただし、モデルベース強化学習とMPCは同一の概念ではありません。
実際の産業ロボットや製品レベルのシステムでは、強化学習単独ではなく、従来の制御手法や模倣学習と組み合わせて用いられることが一般的です。
強化学習をロボットに適用する際の課題
- 学習効率の問題:多くの試行回数が必要になる場合があります
- 報酬設計の難しさ:不適切な報酬は、意図しない行動を最適化してしまう可能性があります
- 安全性の確保:探索過程で危険な行動を取るリスクがあります
これらの課題に対しては、安全制約付き強化学習や、人間のデモンストレーションを活用する手法などが研究されています。
まとめ
強化学習は、ロボットに対して試行錯誤を通じて自律的に行動を獲得する能力を与える技術です。
従来の制御理論だけでは対応が難しかった不確実な環境への適応を可能にする一方で、学習効率や安全性といった課題も抱えています。
そのため、強化学習は万能な解決策としてではなく、ロボット知能を拡張するための重要な構成要素の一つとして、他の手法と組み合わせながら活用されているのが現状です。
以上、強化学習とロボットの関係性についてでした。
最後までお読みいただき、ありがとうございました。