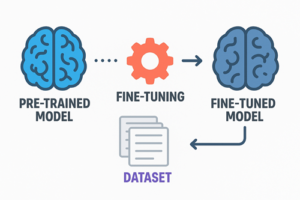

ファインチューニング(Fine-Tuning)は、既に事前学習された大規模モデルに追加データを与え、特定の用途に適応させるための再学習プロセスです。
ゼロからモデルを訓練する場合と比較して、必要なデータ量・計算資源が大幅に少なく、特定タスクに最適化された性能を実現できます。
ファインチューニングが必要になる背景
汎用モデルは多様なデータで学習されているため幅広く対応できますが、次のようなケースではそのままでは不十分になることがあります。
- 特定分野の専門用語や文脈理解を強化したい
- 特定の文体・ルールに沿った出力を安定して生成したい
- 独自タスクに合った高精度なモデルが必要
このギャップを埋めるために、用途に応じたファインチューニングが行われます。
ファインチューニングの代表的な手法
ファインチューニングには多様なアプローチがありますが、大きく次のカテゴリに分類されます。
フルファインチューニング(Full Fine-Tuning)
概要
モデルの全パラメータを再学習する方式です。
特徴
- 柔軟性が高く、データを強く反映できる
- 計算コストが非常に大きい
- モデル全体の挙動が変わるため注意が必要
適するケース
- 大規模データセットを用意できる場合
- 完全特化したモデルが求められる場合
パラメータ効率型ファインチューニング(PEFT)
フルファインチューニングと異なり、学習すべきパラメータを最小限に抑える手法群です。
現在主流となっており、高性能な大規模モデルでも効率的に再学習できます。
代表例
- LoRA(Low-Rank Adaptation)
- QLoRA(量子化+LoRA)
- Prefix Tuning
- Adapter Tuning
LoRA(Low-Rank Adaptation)
仕組み
- 元の重みWは凍結したまま、追加の低ランク行列 ΔW を学習する方式
- ΔW は A と B の積で表現される低次元成分として学習される
W' = W + ΔW
ΔW = A B
メリット
- メモリ・計算コストが大幅に削減
- 小規模GPUでも学習可能
- アダプタ切り替えにより複数用途へ対応しやすい
QLoRA
LoRAをさらに効率化するために、ベースモデルを4bit量子化してメモリ使用量を劇的に減らした手法。
特徴
- 大規模モデルでも低コストでファインチューニング可能
- 性能劣化が比較的少ない
- ハードウェア要件を大幅に緩和
指示調整(Instruction Tuning / Supervised Fine-Tuning)
概要
入力と望ましい出力のペアを与え、モデルにタスク遂行能力や指示への従順性を身につけさせる手法です。
例
入力:レポートの要点をまとめてください
出力:要点1、要点2、…
用途
- 指示の解釈能力を向上させる
- 特定形式の文章生成を安定させる
- 特定タスク(分類・要約・変換など)に特化させる
RLHF / RLAIF(フィードバックによる強化学習)
RLHF(Reinforcement Learning from Human Feedback)
モデルが生成した複数の回答に対して人間がランキングを付け、その情報をもとに「報酬モデル(Reward Model)」を学習し、強化学習(PPOなど)で性能を最適化する手法です。
RLAIF(AI Feedback)
フィードバックを人間ではなく別のLLMが代替することでコストを下げた方式。
役割
- 出力の望ましさや安全性を高める
- 曖昧な指示への対応を改善する
- 長文生成などの品質向上に有効
学習データの重要性
モデルの性能はファインチューニングデータの質に大きく依存します。
良いデータの条件
- 一貫性のある文体や形式
- 正確で具体的な内容
- タスクに合った明確なペアデータ
- ノイズや矛盾が少ない
質の高いデータは、少量でも大きな性能向上につながります。
ファインチューニングとRAGの違い
RAG(Retrieval-Augmented Generation)との比較は重要です。
| 手法 | 強み | 弱み |
|---|---|---|
| ファインチューニング | モデル内部に知識が統合され、自然で高速な推論が可能 | 知識を更新するには再学習が必要 |
| RAG | データ更新のみで最新化が可能 | 検索失敗時に誤答が出やすい |
総括すると:
- 長期的に変わらない知識 → ファインチューニング
- 頻繁に更新される情報 → RAG
- 両方必要 → RAG+PEFT(LoRAなど)の併用
という構成がよく採用されています。
用途別の最適手法
目的に応じて選ぶべき手法は明確に異なります。
- 文体・生成形式の調整 → SFT / LoRA
- 特定知識の埋め込み → LoRA / QLoRA
- 最新情報の反映 → RAG
- 安全性・一貫性の向上 → RLHF
今後のトレンド
- 複数LoRAアダプタを統合するアプローチの進展
- 軽量SFTとモデルオーケストレーションの一般化
- 継続学習の実用化
- RLAIFによる低コスト強化学習の普及
これらの動向により、モデルカスタマイズはさらに柔軟で低コストになっていくと考えられています。
まとめ
ファインチューニングは大きく次の手法に分類できます。
- フルファインチューニング
- PEFT(LoRA / QLoRA など)
- SFT(教師あり微調整)
- RLHF / RLAIF(フィードバック学習)
特性・目的・更新頻度に応じて使い分けることで、効率的にモデルを最適化できます。
以上、ファインチューニングの手法についてでした。
最後までお読みいただき、ありがとうございました。