
強化学習(Reinforcement Learning)とは、行動の結果として得られる「報酬」を手がかりに、将来的により良い結果を生む行動を学んでいく学習方法です。
あらかじめ「この行動が正解」と教えられるのではなく、実際に行動した結果が良かったか悪かったかという評価を受け取りながら、試行錯誤を通じて行動の選び方を改善していく点が特徴です。
経験から学ぶ仕組み
強化学習は、人間や動物が経験から学ぶ過程に非常に近い考え方です。
たとえば、ある行動を取った結果、良いことが起きればその行動は繰り返されやすくなり、悪い結果につながれば、次は別の行動を試すようになります。
AIにおける強化学習も同様に、行動 → 結果 → 評価 → 行動の修正というサイクルを何度も繰り返すことで、より適切な判断を身につけていきます。
強化学習を構成する主な要素
強化学習は、いくつかの基本要素の組み合わせで成り立っています。
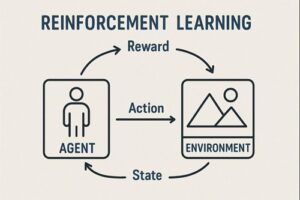
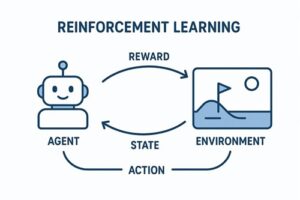
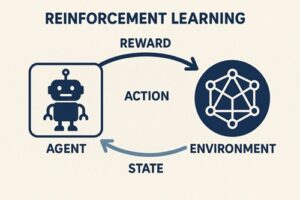
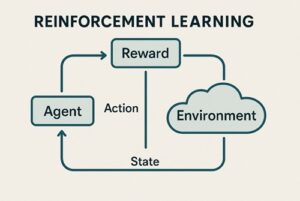
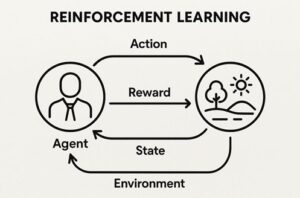
エージェント
学習し、意思決定を行う主体です。
AIプログラムやロボット、ゲーム内のキャラクターなどが該当します。
環境
エージェントが行動する世界や状況のことです。
ゲームのステージ、道路状況、シミュレーション空間などが環境になります。
状態
環境の現在の状況を表す情報です。
エージェントはこの状態を観測し、次の行動を判断します。
行動
エージェントが選択できる行為の集合です。
進む、止まる、操作するなどが行動に含まれます。
報酬
行動の結果として与えられる評価です。
良い結果には正の報酬、望ましくない結果には負の報酬が与えられます。
学習の流れ
強化学習では、次のような流れが繰り返されます。
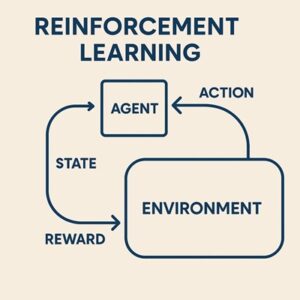
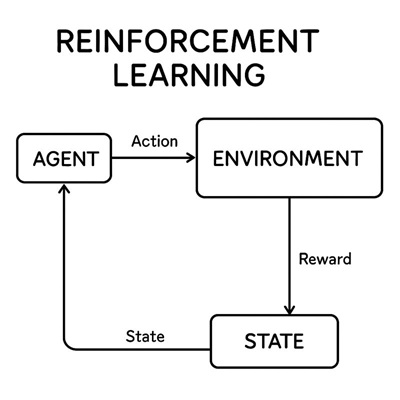
- エージェントが現在の状態を観測する
- 状態に基づいて行動を選択する
- 環境が変化し、報酬が返される
- 将来より多くの報酬を得られるよう、行動の選び方(方策)を更新する
重要なのは、目の前の報酬だけでなく、将来も含めた「累積報酬」を最大化しようとする点です。
他の機械学習との違い
教師あり学習との違い
教師あり学習では、入力データに対する正解ラベルがあらかじめ用意されています。
一方、強化学習では、各行動の正解は直接与えられず、行動の結果として得られる評価のみが示されます。
エージェントは、その評価をもとに どの行動が望ましいかを自ら学びます。
教師なし学習との違い
教師なし学習は、データに潜む構造や特徴を発見することを目的とします。
強化学習では、行動が環境に影響を与え、その結果が次の学習に反映されるという点が大きな違いです。
強化学習が活用される分野
強化学習は、次のような領域で活用されています。
- ゲームAI(囲碁・将棋・ビデオゲーム)
- ロボット制御や自動運転
- 生産・物流の最適化
- 広告配信やレコメンドの最適化
- 金融分野における意思決定支援
代表例として知られる AlphaGo Zero は、人間の棋譜を使わず、自己対戦を通じた強化学習によって高い性能を獲得しました。
強化学習の課題
強化学習は強力な手法ですが、いくつかの難しさもあります。
- 試行錯誤が多く、学習に時間がかかる
- 報酬の設計次第で、意図しない行動を学習してしまうことがある
- 現実世界では失敗のコストが高い
そのため、実務ではシミュレーション環境で十分に学習させたうえで実環境に適用するというアプローチが一般的です。
まとめ
- 強化学習は、行動の結果として得られる報酬を手がかりに学習する方法
- 正解は直接与えられず、試行錯誤を通じて行動を改善する
- 将来を含めた累積報酬を最大化することが目的
- 人間の「経験から学ぶ」仕組みに近い
この理解を土台にすれば、Q学習、方策勾配法、深層強化学習(Deep Reinforcement Learning)といった発展的な内容にも無理なく進めます。
最後までお読みいただき、ありがとうございました。