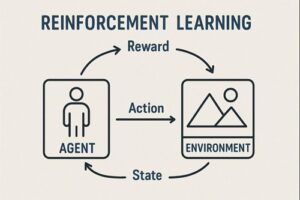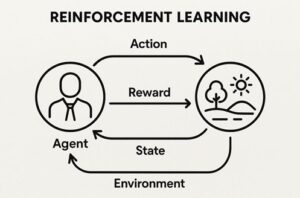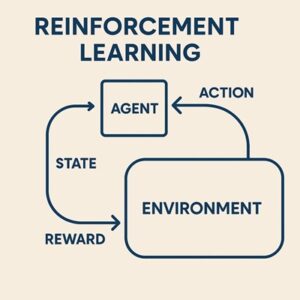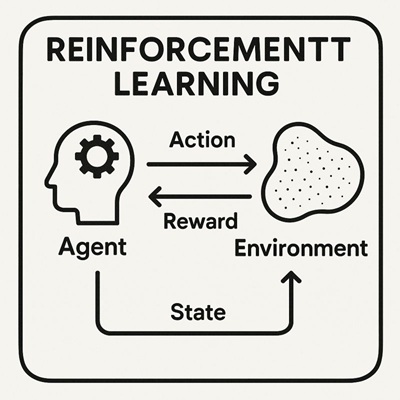

強化学習における方策とは、「ある状態に置かれたとき、エージェントがどの行動を選ぶかを決めるルール」です。
重要なのは、方策は単なるルールではなく、学習の最終成果物そのものであるという点です。
強化学習は「良い行動を覚える学習」ではなく、「良い行動選択の仕組み(方策)を作る学習」だと捉える方が正確です。
方策は「確率」を含むことが多い
方策には大きく分けて2種類があります。
決定論的な方策
- 状態が決まれば、行動は常に同じ
- 実行時の挙動が安定している
- ただし探索が弱く、最初の学習段階では不利になりやすい
確率的な方策(現代の主流)
- 状態ごとに「行動の出やすさ(確率)」を持つ
- 同じ状態でも異なる行動を取る可能性がある
- 探索と活用を自然に両立できる
現在の深層強化学習では、確率的方策を前提にした設計がほぼ標準です。
方策と「探索」の関係を正しく整理する
強化学習では常に「探索」と「活用」のバランスが問題になります。
- 探索:まだ試していない行動をあえて試す
- 活用:今までで良いと分かっている行動を使う
ε-greedy の位置づけ(誤解しやすい点)
ε-greedy は「方策そのもの」というより、価値を使って行動を選ぶ際の“探索ルール”として使われることが多い手法です。
- 主に価値ベースの手法で使われる
- 方策勾配系では、確率分布やランダム性そのものが探索の役割を果たす
- そのため PPO などでは ε-greedy はほぼ使われない
方策の「表現方法」が性能を左右する
方策は、どう表現するかによって扱える問題の範囲が大きく変わります。
小規模問題
- 状態と行動の対応表として持つ
- シンプルだが拡張性がない
実務・現実的な問題
- ニューラルネットワークで方策を表現
- 状態を入力すると、行動の確率分布が出力される
- 画像・ログ・連続値なども扱える
現在の強化学習は、「方策=ニューラルネットワーク」という前提で語られることがほとんどです。
方策ベース手法の正確な説明
方策ベース手法とは、「行動の良し悪しを通じて、方策そのものを直接改善するアプローチ」です。
重要なポイントは次の2点です。
- 良い結果につながった行動は、将来選ばれやすくする
- 悪い結果につながった行動は、選ばれにくくする
この考え方自体は非常に直感的ですが、そのままでは学習が不安定になるため、評価役(価値関数)を併用するのが一般的です。
Actor-Critic における方策の役割
現在の主流構造である Actor-Critic では役割が分かれています。
- Actor(方策)
- 実際に行動を選ぶ
- 確率的に行動を出力することが多い
- Critic(価値関数)
- その行動がどれくらい良かったかを評価する
- Actor の更新を安定させるために存在する
つまり、方策は単独で学習されることは少なく、評価役とセットで使われるのが現代的な姿です。
価値ベース手法との違い(誤解を避けた表現)
よくある単純化された比較ではなく、正確に整理します。
- 価値ベース手法
- 「どの行動が良いか」を数値で学習する
- 行動選択はその数値を見て決める
- 古典的には離散行動向き
- 方策ベース手法
- 「どう行動を選ぶか」を直接学習する
- 行動選択が学習対象そのもの
- 連続行動や確率的制御に向いている
実際の現場では、両者を組み合わせた手法(Actor-Critic)が主流です。
実務視点での方策の重要性
実際の応用(ロボット制御、広告配信、価格最適化など)では、
- 行動が連続値
- 状態がノイズを含む
- 正解が一つではない
といった条件が普通です。
そのため、
- 確率的方策
- ニューラルネットワーク表現
- 安定更新(PPOなど)
を前提に方策を設計することが、現代的な強化学習の基本になっています。
まとめ
- 方策は「行動を決める仕組み」であり、学習の最終成果
- 現代の強化学習では確率的方策が標準
- 方策は直接学習されるが、評価役(価値関数)と組み合わせるのが一般的
- ε-greedy は主に価値ベース向けの探索ルール
- 実務では Actor-Critic + PPO 系が主流
以上、強化学習の方策についてでした。
最後までお読みいただき、ありがとうございました。