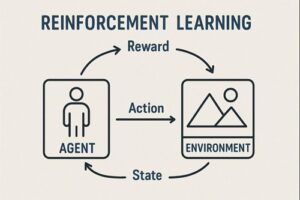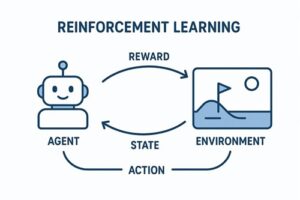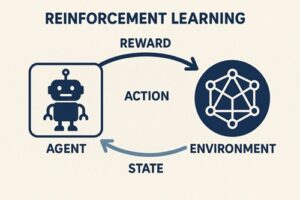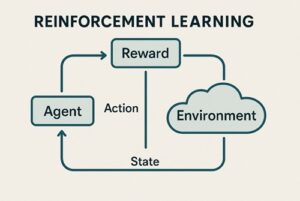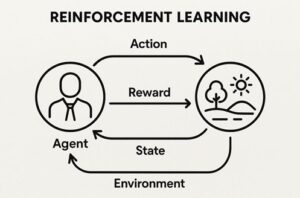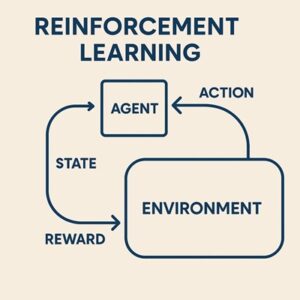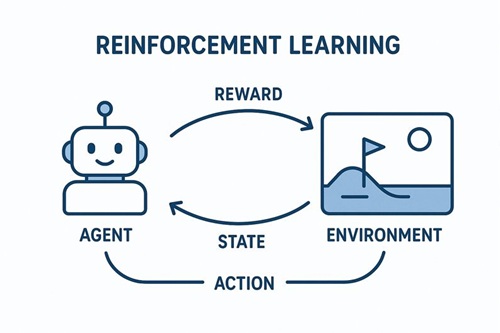

強化学習(Reinforcement Learning, RL)において環境(Environment)は、単なる舞台装置ではありません。
環境は、エージェントが学習する「世界のルール」そのものであり、学習の成否を大きく左右する最重要要素です。
実際、アルゴリズムをどれだけ高度にしても、環境設計が不適切であれば、学習は進まないか、誤った行動を学習してしまいます。
環境とは何か(定義)
強化学習における環境とは、次のように定義できます。
エージェントの行動を受け取り、その結果として次の状態(または観測)、報酬、終了条件を返す仕組み全体
重要なのは、環境が「状態」「報酬」「遷移ルール」「制約」「終了条件」などを一体として内包している点です。
エージェントは環境の内部構造を直接操作できず、行動(Action)を通じてのみ間接的に影響を与えるという前提で設計されます(※多くのモデルフリーRLの場合)。
エージェントと環境の相互作用ループ
強化学習は、以下のステップを繰り返すことで進行します。
- 環境が現在の状態(または観測)を提示する
- エージェントが行動を選択する
- 環境が以下を返す
- 次の状態(または観測)
- 報酬
- エピソード終了かどうか
このループを通じて、エージェントは「どの行動が将来的により高い累積報酬をもたらすか」を学習します。
環境の理論的定式化:MDP(マルコフ決定過程)
多くの強化学習問題は MDP(Markov Decision Process) として定式化されます。
基本構成要素(代表的定義)
MDPは通常、以下の4要素で表されます。
- S(States):状態の集合
- A(Actions):行動の集合
- P(Transition Probability):状態遷移確率
- R(Reward Function):報酬関数
実務や教科書では、これに加えて以下も重要になります。
- γ(割引率, discount factor)
- 初期状態分布
- 終端状態(terminal states)
これらを含めて初めて「最適方策を定義する問題設定」が完成します。
環境を構成する主要要素の詳細
状態(State)と観測(Observation)
- 状態(State)
環境の真の内部状態。理論上は完全な情報を含む。 - 観測(Observation)
エージェントが実際に受け取れる情報。
完全観測環境では「状態=観測」と見なせますが、現実世界や多くの実問題では部分観測(POMDP)となり、観測にはノイズや欠落が含まれます。
その場合、エージェントは観測列から状態を推定しながら行動する必要があります。
行動(Action)
エージェントが選択できる操作の集合です。
- 離散行動:上下左右、選択肢A/B/C
- 連続行動:角度、速度、力、価格調整量
行動空間が広い・連続になるほど、環境は難しくなり、アルゴリズム選択にも影響します。
報酬(Reward)
環境がエージェントの行動結果を評価するスカラー値です。
- 即時に与えられることも
- 長期的に遅れて影響することもあります
報酬設計は環境設計の中でも特に失敗しやすく、影響の大きい要素です。
- 報酬が疎すぎる → 学習が進まない
- 報酬が歪んでいる → 本来の目的と異なる行動を学習(報酬ハッキング)
そのため「環境設計の要」と言われることが多いのです。
遷移(Transition)
行動によって状態がどのように変化するかを定めるルールです。
- 決定論的:同じ状態・行動なら必ず同じ結果
- 確率的:結果が確率分布に従って変化
現実世界の問題は、ほぼ例外なく確率的遷移を含みます。
環境の性質による分類
決定論的 / 確率的
- 決定論的:チェス、将棋
- 確率的:ロボット制御、金融、ユーザー行動
エピソード型 / 継続型
- エピソード型:1ゲームで終了
- 継続型:制御・最適化タスク
完全観測 / 部分観測
- 完全観測:盤面がすべて見える
- 部分観測:センサノイズ、隠れ状態あり
実装上の「環境」:Gymnasium形式
研究・実務で広く使われるのが Gymnasium(旧OpenAI Gym)形式です。
基本的なインターフェース(Gymnasium準拠)
obs, info = env.reset()
obs, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
- terminated:タスク上の成功・失敗などで自然に終了
- truncated:時間制限など外的理由で打ち切り
環境の責務は以下を含みます。
- 初期状態の生成
- 状態遷移の計算
- 報酬の計算
- 終了条件・制約の管理
エージェント側は、環境をブラックボックスとして扱うのが基本です(モデルフリーRLの場合)。
環境設計で起きやすい失敗
- 報酬ハッキング
本来の目的と異なる行動を最適化してしまう - 状態情報不足
学習に必要な情報が観測に含まれていない - 難易度が高すぎる初期環境
→ カリキュラム学習が有効
多くの場合、アルゴリズムではなく環境設計が原因です。
現実世界における環境の難しさ
現実環境では以下の問題が顕著です。
- ノイズが多い
- 安全制約が厳しい
- 試行回数が限られる
- 環境が時間とともに変化する(非定常)
そのため、
- シミュレーション環境で学習
- 実環境へ転移(Sim-to-Real)
という戦略が取られます。
まとめ:環境は「学習世界の設計図」
- 環境は単なる入出力の箱ではない
- 報酬・状態・遷移・制約は不可分
- 学習がうまくいかないとき、まず環境を疑うべき
強化学習ではしばしば、
「アルゴリズムを疑う前に、環境を疑え」
と言われます。
それほどまでに、環境は強化学習の本質的要素です。
以上、強化学習の環境についてでした。
最後までお読みいただき、ありがとうございました。