
強化学習(Reinforcement Learning, RL)は、自動運転技術の文脈で頻繁に語られる手法の一つです。
しかし実際には、「強化学習が自動運転をそのまま実現する」という単純な関係ではなく、自動運転システムの一部機能を補完・高度化する技術として位置づけられています。
本稿では、自動運転の全体構造を踏まえながら、強化学習がどの領域で使われ、なぜ研究が進められているのか、そして実用上どのような制約があるのかを整理します。
強化学習の基本構造(自動運転向け整理)
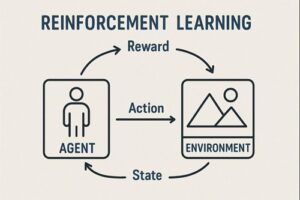
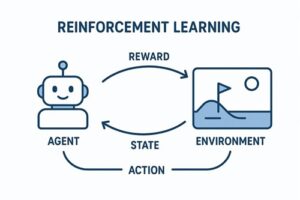
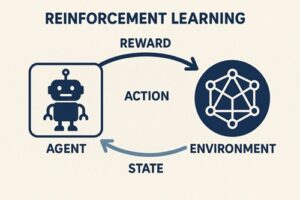
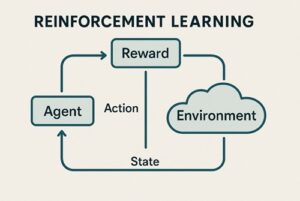
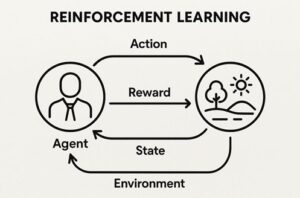
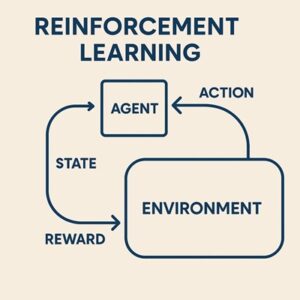
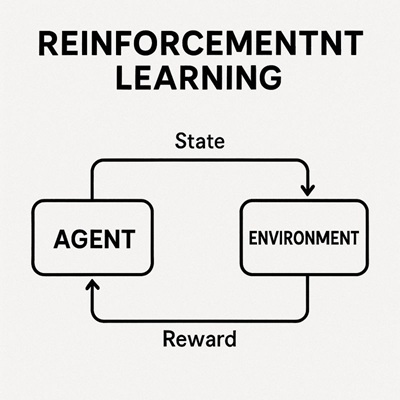
強化学習は、以下の要素で構成されます。
- エージェント(Agent)
行動を決定する主体。自動運転では車両の意思決定・制御アルゴリズムに相当します。 - 環境(Environment)
道路構造、交通状況、他車両、歩行者、天候など、車両を取り巻く外界。 - 行動(Action)
ステアリング操作、加速・減速などの制御入力。 - 報酬(Reward)
行動結果を数値化した評価指標。安全性、快適性、効率性、法規遵守などが反映されます。
強化学習の特徴は、正解行動を事前に与えず、試行錯誤を通じて「累積報酬を最大化する行動方策」を獲得する点にあります。
この性質が、自動運転における複雑な判断問題と相性が良いとされています。
自動運転システム全体における位置づけ
自動運転は、一般に次の三層構造で整理されます。
認識(Perception)
- カメラ、LiDAR、レーダーなどのセンサー情報を解析
- 車線、信号、歩行者、他車両を検出・追跡
- 教師あり学習や自己教師あり学習が主流
この領域では、安定性と再現性が重視されるため、強化学習が主役になることは多くありません。
判断・計画(Decision / Planning)
- 車線変更や追い越しの判断
- 合流・交差点での進行可否判断
- 周囲車両との相互作用を考慮した行動選択
この領域は、研究・実証段階において強化学習が特に多く検討されている分野です。
長期的な影響を考慮した意思決定が必要となるため、累積報酬最大化の枠組みが適しています。
制御(Control)
- ハンドル角、アクセル、ブレーキ量の算出
- 従来はPID制御やモデル予測制御(MPC)が中心
一部の研究では、連続制御問題として強化学習が用いられますが、実運用では既存の制御理論と組み合わせる設計が一般的です。
なぜ自動運転で強化学習が研究されるのか
ルールベース設計の限界
現実の交通環境では、すべての状況を明示的なルールで記述することは困難です。
- 曖昧な優先関係
- 人間ドライバーの非定型な挙動
- 相互に影響し合う複数車両の行動
強化学習は、これらを報酬設計という形で間接的に表現できる点が評価されています。
長期的な最適化が可能
短期的には非効率に見える行動であっても、将来的に安全性や円滑性が向上する場合があります。
強化学習では、こうした判断を長期的な累積報酬の最大化問題として自然に扱えます。
シミュレーション環境との親和性
自動運転分野では、高精度シミュレーターを用いて、
- 危険な状況
- 発生頻度の低いエッジケース
- 複雑な交通シナリオ
を安全かつ大量に生成できます。
ただし、シミュレーションでの有効性がそのまま現実に転移するわけではない点は重要な前提です。
強化学習が検討される代表的な応用領域
- 車線変更・追い越し判断
- 高速道路の合流・分流
- 信号なし交差点での進行判断
- 前車追従と車間距離制御
- エネルギー効率を考慮した走行制御(特にEV)
これらはいずれも、他エージェントとの相互作用を含む意思決定問題であり、強化学習の研究対象として適しています。
よく使われる強化学習アルゴリズム
研究・シミュレーション環境で頻繁に用いられる代表例には、以下があります。
- DQN:離散的な行動空間向け
- DDPG / TD3:連続制御タスク向け
- PPO:学習安定性が高く、比較研究で広く使用
- SAC:探索性能に優れ、複雑環境に適応しやすい
なお、これらのアルゴリズムが商用車載システムでそのまま使われているかどうかは、公開情報が限られており一般化はできません。
多くの場合、独自拡張や他手法との組み合わせが行われます。
強化学習と自動運転における主要課題
安全性の確保
強化学習は試行錯誤を前提とするため、現実環境での直接学習は原則として不可能です。
- 安全制約付き強化学習(Safe RL)
- ルールベースによる制限
- 異常時のフェイルセーフ設計
などが不可欠となります。
報酬設計の難しさ
報酬関数の設計次第で、システムの振る舞いは大きく変わります。
設計を誤ると、安全や法規よりも効率を優先する行動が学習されるリスクがあります。
自動運転において、報酬設計は実質的に「どのような運転を良しとするか」という思想の定義に相当します。
Sim-to-Real問題
シミュレーションと実環境の差異により、
- 学習済み方策が実車で機能しない
- 小さな誤差が不安定挙動につながる
といった問題が生じます。
このため、ドメインランダム化や実データを用いた微調整などの工夫が必要になります。
実用システムにおける現実的な位置づけ
現在の自動運転システムでは、
- 認識:教師あり学習
- 安全・基本挙動:ルール・制約ベース
- 一部の判断・最適化:強化学習
というハイブリッド構成が一般的です。
強化学習を単独で全面的な意思決定機構として採用する例は限定的であり、安全性・検証性・説明可能性の観点から補助的に使われるケースが多いのが実情です。
まとめ
- 強化学習は、自動運転における判断・計画・一部制御で有効な研究手法
- 実用では、他の学習手法やルールベース設計と組み合わせて利用される
- 最大の課題は 安全性、報酬設計、Sim-to-Real
- 今後は Safe RLや模倣学習との統合が重要な発展方向となる
以上、強化学習と自動運転の関係性についてでした。
最後までお読みいただき、ありがとうございました。