
強化学習を実装する際に必要となる考え方やプロセスは、驚くほどシンプルな骨格の上に成り立っています。
その全体像をつかむことで、複雑に見えるアルゴリズムやライブラリも一気に理解しやすくなります。
強化学習の実装は「環境」と「エージェント」づくりからはじまる
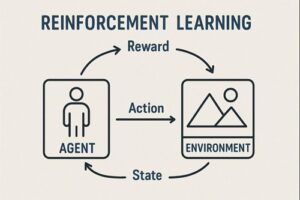
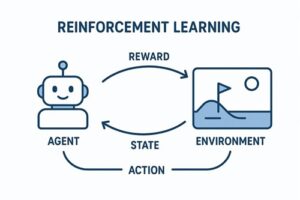
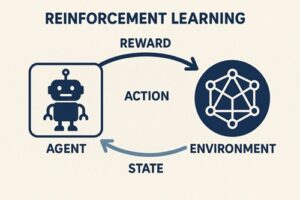
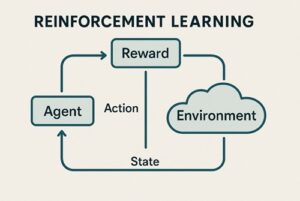
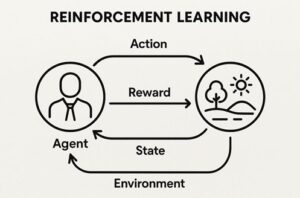
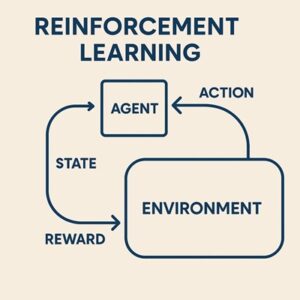
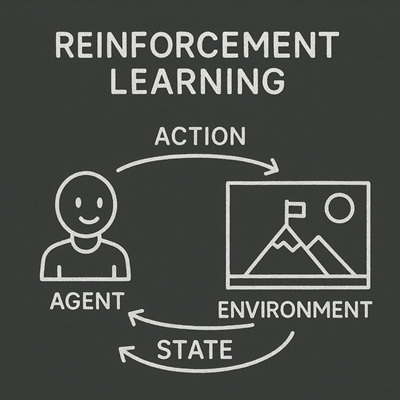
強化学習は、「環境に対して行動し、その結果を学習しながら賢くなっていく仕組み」です。
環境(Environment)
環境は、エージェントが行動する舞台のことです。
操作すると、次の状態・得点(報酬)・終了判定などを返してくれます。
例)
- 迷路
- 棒倒しゲーム(CartPole)
- ロボットのシミュレーション
エージェント(Agent)
エージェントは、環境から観測した状態をもとに次の行動を決める存在です。
経験を蓄積し、より良い判断ができるように「方針(ポリシー)」を更新し続けます。
どんな強化学習でも必ず登場する基本概念
実装の前に、最低限押さえるべき概念があります。
- 状態(State)
エージェントが観測できる世界の情報 - 行動(Action)
エージェントが選べる操作 - 報酬(Reward)
行動の結果として得られるスカラー値(良いときはプラス、悪いときはマイナス) - エピソード(Episode)
開始から終了までの一連の流れ - ポリシー(Policy)
状態ごとにどの行動を選ぶかの戦略 - 価値(Value / Q値)
特定の行動がどれくらい将来の報酬につながりそうかの評価指標
これらが噛み合うことで、学習が成立します。
強化学習実装の基本フロー
どんな手法を使う場合でも、おおむね同じ手順で進みます。
- 環境を初期化する
- 現在の状態を観測する
- 行動を選ぶ(ランダム or 学習済みの戦略)
- 行動を環境に与える
- 次の状態と報酬を受け取る
- 得られた経験を使ってエージェントを更新する
- 終了ならエピソードを終え、次のエピソードへ
- これを何百〜何万回も繰り返す
つまり、「観測 → 行動 → 結果 → 学習」のループを延々と回す仕組みを作ることが重要です。
もっとも基本的な実装イメージ:表形式の Q-learning
Q-learning は「状態 × 行動」すべてに対して、「その行動はどれくらい良いか(Q値)」を表で記録していく手法です。
行動の選び方
よく使われるのが「ε-greedy」という方法で、
- 大半の時間は、Q値がもっとも高い行動を選ぶ(活用)
- 少しの確率だけ、あえてランダムな行動を選ぶ(探索)
というバランスを取りながら学習を進めます。
Q値の更新イメージ
エージェントが行動した結果、
- 報酬が高かった
- 次の状態でより良い行動がとれそうだった
という情報を踏まえて、Q値を少しずつ修正していきます。
Q-learning をニューラルネットで拡張したものが DQN
表形式の Q-learning は、状態が「数個の整数」など単純な環境でしか使えません。
CartPole のように「連続値のベクトル」が状態になる環境では、表では管理ができないため、価値の計算をニューラルネットで置き換える方法が使われます。
これが DQN(Deep Q-Network) です。
DQN で重要な要素
DQN には、学習を安定させるための仕組みがいくつか入っています。
- Q関数をニューラルネットで近似
状態ベクトルを入力し、各行動の価値をまとめて予測します。 - 経験をある程度ためてからランダムに取り出して学習(Experience Replay)
過去の経験をシャッフルしたミニバッチで学習するため、学習が安定する - ターゲットネットワーク
学習中のネットワークを直接使うのではなく、一時的に固定したコピーを参照することで発散を防ぐ - 探索率(ε)を少しずつ減らす
初期はランダム行動中心 → 後半は学習結果を反映した行動中心
学習ループの流れ
DQN では、以下を繰り返します。
- 状態を観測し、行動を選ぶ
- 行動の結果を記録してバッファへ貯める
- 一定量のデータが溜まったらミニバッチで学習
- 時々、ターゲットネットワークを同期する
この仕組みにより、強化学習が比較的安定して進みます。
ポリシーを直接学習する手法(Policy Gradient / Actor-Critic)
Q-learning 系は「価値」を使って間接的に最適な行動を推測しますが、Policy Gradient 系は「行動そのものの確率」を直接学習します。
さらに、価値を推定するネットワークを補助として加えたものがActor-Critic(例:PPO、A2C/A3C) です。
実務でよく使われる強化学習アルゴリズムは、ほとんどがこの Actor-Critic 系に分類されます。
実装する際に必ず直面するポイント
強化学習は思った以上にデリケートで、以下のような要因が結果を大きく左右します。
報酬設計の難易度
報酬が「滅多に出ない」場合、学習が進まないことがあります。
途中経過の成果に小さな報酬を与えると改善されることが多いです。
状態の前処理
観測値を正規化したり、無駄な情報を削除したりすると学習が安定しやすくなります。
ハイパーパラメータの敏感さ
学習率・割引率・探索率の調整は成否を左右する非常に重要な要素です。
可視化とログ取得
学習曲線(報酬の推移)、損失の推移などを必ず記録し、うまくいっているか、発散していないかを目視で確認することが重要です。
学習ロードマップ(これから実装したい人向け)
強化学習を本格的に身につけるには、次のステップで進めるのがおすすめです。
- 表形式の Q-learning を理解する
価値更新の仕組みを小さな環境で体験する - DQN を CartPole などで実装してみる
経験再生・ターゲットネットなど強化学習の基本技術がまとまって学べる - 学習曲線の可視化やデバッグ方法を身につける
「なぜ失敗したか」を読み解く力がつく - PPO などの Actor-Critic 系に進む
実務レベル・コンペレベルの問題に通用する
以上、強化学習の実装方法についてでした。
最後までお読みいただき、ありがとうございました。