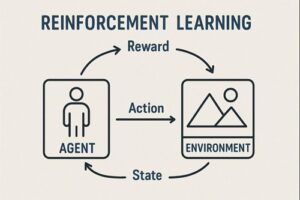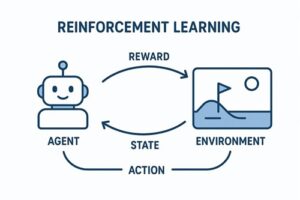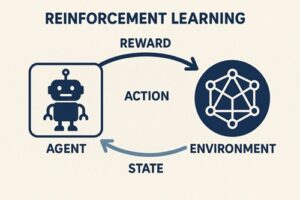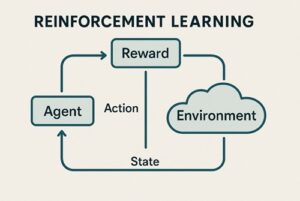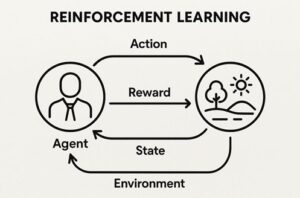

強化学習(Reinforcement Learning, RL)は、「環境の中で試行錯誤しながら、報酬が最大になる行動を学ぶ」ことを目的とする学習手法です。
教師あり学習のように「正解データ」が存在するわけではなく、エージェントが自ら行動し、その結果得られる報酬を手がかりに改善を続ける点が特徴です。
ゲーム分野での代表的な成功事例
ゲームはシミュレーション環境が整っており、強化学習が発展してきた中心領域です。
Atariゲーム(DQN)
Google DeepMind の DQN(Deep Q-Network) は、画面の生ピクセルを入力として扱い、数多くのAtariゲームで人間レベル〜それ以上のスコアを記録しました。
特徴
- 事前にゲームの攻略法を教えない
- 画面だけを見て「価値」を推定し行動する
- 多くのタイトルで高い性能を達成
ゲームAI研究における大きなターニングポイントとなりました。
AlphaGo / AlphaGo Zero / AlphaZero
囲碁AIの飛躍をもたらしたのが AlphaGo です。
AlphaGo は最初に人間棋譜から教師あり学習を行い、その後、自己対局による強化学習で実力を伸ばしました。
その後登場した AlphaGo Zero は、人間棋譜を使わず、ルールだけを与えた状態から完全な自己対局のみで世界トップに到達。
このコンセプトを囲碁以外(チェス・将棋)にも展開したのが AlphaZero です。
チェス・将棋の最新エンジン
AlphaZeroのアプローチを取り込んだエンジンは、従来の探索型エンジンを上回るケースが現れ、戦略ゲームでの強化学習の存在感は一気に高まりました。
産業・工学系での強化学習の応用
ロボット制御(歩行 / 把持 / 安定化)
ロボティクスは、強化学習の実用化が進む代表分野です。
応用例
- 二足歩行ロボットの安定歩行
- アームロボットによる物体の把持(Grasping)
- ドローンの衝突回避や飛行姿勢制御
現実で失敗するとコストが大きいため、まずシミュレーション(MuJoCo など)で学習し、実機へ転移する Sim2Real が重要なテーマとなっています。
自動運転(行動方針の学習)
自動運転車は周囲の状況を判断し、適切な行動を選択する能力が求められます。
強化学習が使われるタスク
- 車間距離の調整
- 車線変更の判断
- 障害物回避の方針学習
実用システムの中核が全面的に強化学習で構成されているわけではありませんが、部分的なタスクやシミュレーション環境での検証に強化学習が積極的に研究されています。
物流・倉庫ロボットの最適化
倉庫ロボット群の動線や協調行動の最適化には、マルチエージェント強化学習(MARL) が有効です。
効果例
- ロボット同士の衝突回避
- ピッキング作業の効率向上
- 全体としての移動コスト削減
複数エージェントが同時に行動する複雑な環境に向いています。
電力・製造などのインフラ領域での活用
スマートグリッド(電力需給の制御)
電力は需要と供給が常に変動しており、強化学習が多くの研究で検討されています。
学習対象となるタスク
- バッテリー貯蔵量の制御
- 再生可能エネルギーの出力変動の調整
- 発電機の最適な切り替え
特に風力・太陽光の不確実性が高い環境との相性が良い分野です。
製造ラインの最適制御(スマートファクトリー)
工場環境でも、強化学習は効果的な最適化手法として注目されています。
応用例
- 生産ラインの停止リスクを最小化
- 機器の稼働スケジュールを最適化
- 温度・湿度・圧力などの環境条件の制御
従来のPID制御では扱いきれない複雑な制御問題に対して活用が期待されています。
医療・科学研究における強化学習の応用
医薬品設計(分子探索)
新しい分子構造を設計する際に、強化学習が有効な探索手法として使われています。
目的
- 望ましい特性(結合力・安定性・毒性の低さなど)を持つ化合物候補を効率的に生成する
分子生成モデルと組み合わせて急速に研究が進む領域です。
個別化医療(治療ポリシー最適化)
患者ごとの時系列データに基づき、治療の最適化を試みる研究があります。
例
- インスリン投与量の調整
- 放射線治療の照射量スケジュール最適化
安全性確保の観点から実用化には慎重な検証が必要ですが、ポテンシャルは大きい分野です。
金融領域での応用
投資・ポートフォリオ最適化
市場の変動に対してどのような投資行動をとるかを学習する研究が多く存在します。
強化学習が担う役割
- リスクとリターンのバランス最適化
- 市場のダイナミクスへの適応
- 長期的報酬を見据えた資産配分戦略
特に深層強化学習を利用した研究が盛んです。
注文戦略(高頻度取引)
市場の高速な変化に応じて、
- 注文タイミング
- 注文量
を最適化する試みも行われています。
ただし、市場ノイズやリスク管理の複雑さから、実運用への適用は慎重な姿勢が求められています。
強化学習が特に力を発揮する条件
強化学習が適しているのは次のような状況です。
- 明確な正解が存在しない
- 行動の結果が遅れて返ってくる(Delayed Reward)
- 状況に応じて最適行動が変化する
- シミュレーション環境で大量の試行が可能
これらの性質を持つ領域で、強化学習は強力に機能します。
学びを進めるための手法の流れ
強化学習を体系的に理解するには、以下の順番が自然です。
- Q-Learning
- Deep Q-Network(DQN)
- Policy Gradient
- Actor-Critic
- PPO(Proximal Policy Optimization)
- マルチエージェントRL(MARL)
特に PPO は多くの実装や応用研究で採用されており、安定性と取り扱いやすさで人気の高い手法です。
まとめ
強化学習は、
- ゲーム
- ロボット制御
- 自動運転
- 製造・電力制御
- 医療
- 金融
など、多岐にわたる領域で成果をあげています。
「正解がない状況で試行錯誤を通じて戦略を洗練させる」という性質から、複雑な環境下の意思決定問題に対して非常に有効です。
以上、強化学習の事例についてでした。
最後までお読みいただき、ありがとうございました。