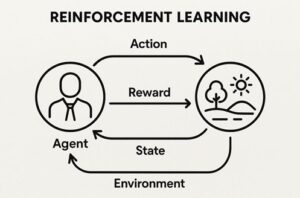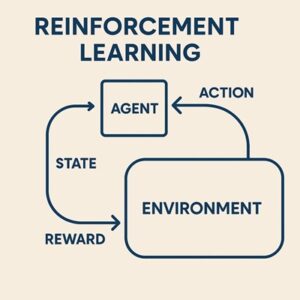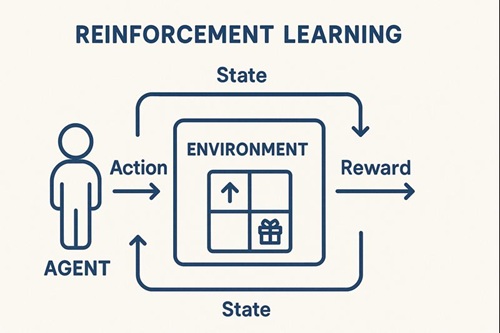

SAC(Soft Actor-Critic)は、強化学習の中でも特に高い安定性と学習効率を兼ね備えた手法として人気があります。
特徴的なのは、「報酬の最大化」だけでなく “行動の多様性(ランダムさ)も評価する” 点にあります。
一般的な強化学習は、良い行動だけをひたすら選び、探索が不足しがちです。
一方 SAC では、「良い行動を選びつつ、探索も続ける」 というバランスを自動的に保ちながら学習します。
その結果、他の手法に比べて
- 学習が破綻しにくい
- サンプル効率が高い(少ないデータでも学習できる)
- 連続値の行動を扱うタスクで非常に強い
といった特長を持っています。
SAC の中身をやさしく分解すると?
SAC の内部には、役割が異なる複数のネットワークが存在します。
現在主流の「SAC v2」では、次の 5 つ が使われます。
Actor(行動を決めるネットワーク)…1つ
確率的に行動を選び、探索と活用のバランスをコントロール。
Critic(行動の価値を評価するネットワーク)…2つ
行動の良し悪しを判定する。
2つ用意して、小さい値の方を使うことで「価値の過大評価」を防ぐ。
Critic のターゲットネットワーク…2つ
学習を安定させるための補助ネットワーク。
SAC の学習プロセスを“動き”で理解する
SAC の学習は、大きく次のステップで進みます。
経験を貯める(Replay Buffer)
環境と対話し、「状態・行動・報酬・次の状態」という一連の経験を蓄積します。
SAC は“オフポリシー”手法なので、過去のデータを何度も再利用でき、データ効率が非常に良いのが特徴です。
Critic(価値評価)を更新
“次の状態で取りそうな行動”と、そのときの評価をもとに「今の行動はどれくらい良かったのか?」を学習します。
このとき、行動の多様性(ランダムさ)も考慮されるため、価値の計算は探索を意識したものになります。
Actor(行動方策)を更新
Critic が評価した価値と、行動のランダム性を天秤にかけながら
- 一貫して良い行動を選びやすく
- しかし探索も適度に続けられるように
という方向でポリシーを調整していきます。
ターゲットネットワークをゆっくり更新
Critic の安定性を高めるため、“少しだけ古いコピー”をなめらかに更新し続けます。
SAC の強み
とにかく安定して学習しやすい
行動の多様性を保ちながら学習するため、極端な解にハマってしまう可能性が非常に低いです。
連続アクションに強い
力加減や角度、速度など細かい調整が必要なタスクで抜群の性能。
例
- ロボットアーム操作
- ドローン制御
- 自動運転のステアリング調整
- ファイナンスのポートフォリオ最適化
データ効率が高い
Replay Buffer を使うため、体験したデータを何度も再利用できます。
リアル環境のように「データ収集が高コスト」な場面で強いです。
ハイパーパラメータに強い(壊れにくい)
DDPG や PPO に比べると、パラメータの微調整への依存度が小さく、初学者でも扱いやすい手法です。
SAC の弱み
計算コストが重い
Actor + Critic×2 + Target Critic×2
合計 5 つのネットワークを管理するため、動作が重くなりがち。
実装がやや複雑
ネットワーク数も多く、更新式も複雑なため、DDPG や PPO よりもコード量は増えます。
離散アクションにはそのまま使えない
SAC は元々「連続アクション」向けに設計されています。
ただし、離散アクションに対応する“Discrete SAC”という発展版も存在します。
SAC を実装する際のポイント
ネットワークは2〜3層のMLPで十分
各層のユニット数は 256〜512 が一般的。
エントロピー係数(探索量)は自動調整を使う
SAC の大きな利点のひとつ。
探索と活用のバランスをネットワーク自身が自動で最適化してくれます。
Replay Buffer は大きめに
最低でも数十万〜100万ステップ程度あると安定。
正規化(LayerNorm や BatchNorm)は必要ないことが多い
余計に不安定になるケースもあり、まずは“正規化なしの MLP”が推奨されています。
まとめ:SAC は「安定した強化学習」を実現する強力な手法
SAC は、
- 探索が継続しやすい
- 学習が破綻しにくい
- データ効率が高い
- 連続アクションタスクに強い
といった理由から、現代の強化学習でもトップクラスに人気の手法です。
実装こそ少し複雑ですが、その性能は間違いなく本物。
ロボティクスや自動運転、金融などの実世界タスクでも活躍しています。
以上、SACを用いた強化学習についてでした。
最後までお読みいただき、ありがとうございました。