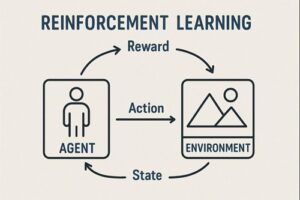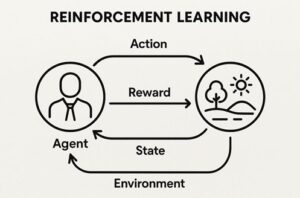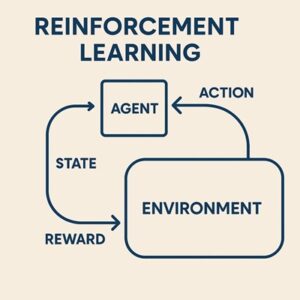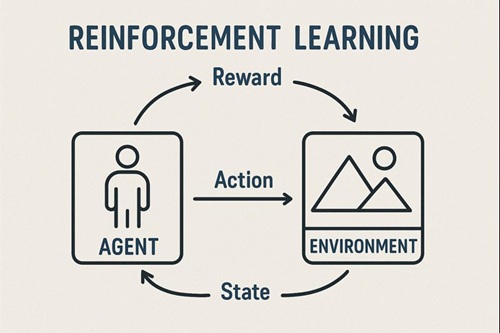

強化学習では、エージェントが環境の中で行動し、その結果として得られる“報酬”を手がかりに学習を進めていきます。
このとき、報酬をどのように与えるかを決めるのが報酬関数であり、強化学習全体の方向性を決める根幹となる仕組みです。
報酬関数は、環境がエージェントに対して
「どんな行動を望んでいるのか」
を数値で伝えるルールのことです。
報酬関数とは何か?
報酬関数は、ある行動を取ったときに返される評価のようなもので、エージェントはその評価を最大化する方向へ学習していきます。
たとえば、
- 目標に近づいたらプラス
- 危険な行動をしたらマイナス
- 成功したら大きなプラス
というように、環境の動作目的を数値で表現したものが報酬関数です。
また、報酬は毎回決まった値とは限らず、同じ行動でも“ランダムな要素”を含んで返ってくることがあります。
強化学習のアルゴリズムは、この不確実性を考慮しながら最適な行動を学習します。
報酬設計が難しい理由
報酬を与えるだけなら簡単に思えますが、実際には以下のような理由で非常に難易度が高い作業です。
理由1:成功までの過程を教える必要がある
最終的に成功した時だけ報酬を与えると、エージェントは学習の初期段階で「何をすれば良いのか」がわかりません。
理由2:意図しない行動が強化されてしまう
目標と報酬がズレていると、エージェントは“数値上だけ得する行動”を強化してしまうことがあります。
これがいわゆる 報酬ハッキング と呼ばれる現象です。
理由3:報酬が細かすぎても逆効果
細かく細かく評価しすぎると、エージェントの行動がその小さな指標に最適化され、より本質的な動作を学習できないことがあります。
報酬の種類と特徴
即時報酬
行動したその瞬間に得られる報酬です。
典型的には、
- 良い行動 → 小さなプラス
- 悪い行動 → 小さなマイナス
といった形で与えます。
短期的な行動評価を明確にしたい場合に有効です。
スパース報酬(希薄な報酬)
成功したときなど、限られたタイミングでだけ報酬が発生するものです。
例
- ゴールに到達したときだけ報酬が発生する
- パズルを解いた瞬間にだけ報酬が得られる
成功までが遠いタスクの場合、探索が非常に難しくなります。
形状報酬(Reward Shaping)
学習を助けるための“補助的な報酬”です。
- ゴールに近づいたら少しプラス
- 逆方向に進んだら少しマイナス
といった形で、エージェントが学習すべき方向を示すことができます。
ただし、補助報酬を与えすぎると、本来目指すべき動作が変わってしまう危険もあるため、慎重に設計する必要があります。
ペナルティ(罰則的な報酬)
行動コストや安全性を考慮するための「減点」の仕組みです。
例
- 急激な動きに対して小さなマイナス
- 衝突や危険行動に対して大きなマイナス
- 無駄なエネルギーを使うとマイナス
ロボット制御などでよく用いられます。
長期的価値を考慮する報酬
強化学習の特徴は、目先の利益だけを追わないことにあります。
エージェントは、「今の報酬だけでなく、将来得られるかもしれない報酬もまとめて大事にする」という学習の仕組みを持っています。
これにより、短期的には損でも、長期的には得になる行動を選べるようになります。
報酬設計の基本原則
原則1:エージェントは“報酬値だけを見て学ぶ”
エージェントは報酬の意味を理解しません。
ただ単純に「数値が大きくなる方向へ進む」だけです。
そのため、報酬と目的が少しでもズレると、望ましくない行動が強化されてしまいます。
原則2:目的と報酬は一致させなければならない
報酬が意図と一致していないと、
- 本来の成功ではない行動
- バグ的な振る舞い
などが“高評価”として扱われるようになります。
これが報酬ハッキングの典型例です。
原則3:探索のしやすさと安定性を両立させる
- 報酬が粗すぎると、成功まで辿り着けない
- 報酬が細かすぎると、局所的な解に埋もれてしまう
このバランスが報酬設計の最も重要な要点です。
報酬設計の進め方
- タスクの最終的な目的を定義する
何を成功とみなすのかを明確にする。 - 望ましい行動を整理し、それに報酬を与える
- 望ましくない行動を洗い出し、ペナルティを設定する
- 短期と長期のどちらを重視するかを決める
- 報酬の大きさのバランスを調整する
報酬の強弱が極端だと学習が不安定になる。 - 実験を繰り返しながら報酬関数を改善する
報酬設計は“作って終わり”ではなく、改善が必須。
まとめ
- 強化学習の報酬関数は、エージェントにとって「行動の基準」を示す最も重要な要素。
- 報酬設計が誤ると、望ましくない行動や報酬ハッキングが発生しやすくなる。
- 即時報酬・スパース報酬・形状報酬・ペナルティ・長期価値など、複数の観点から報酬を設計する必要がある。
- 報酬設計は反復的なプロセスであり、実験しながら改善していくことが成功の鍵。
以上、強化学習の報酬関数についてでした。
最後までお読みいただき、ありがとうございました。