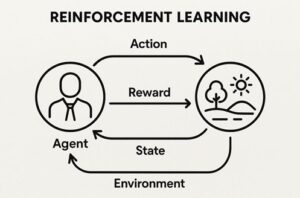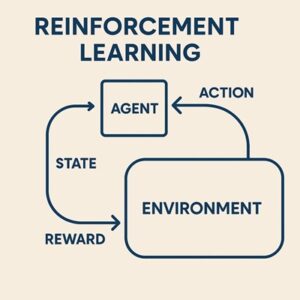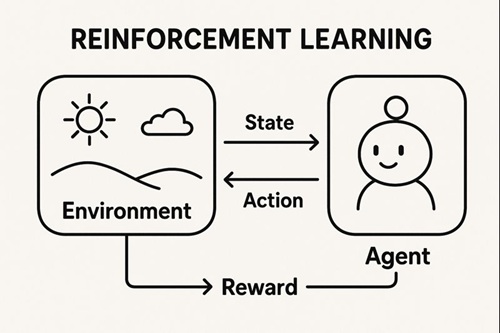

強化学習(Reinforcement Learning; RL)の中心的な概念が「ポリシー(policy)」です。
ポリシーとは簡単に言うと、エージェントが「どんな状況でどんな行動を選ぶか」を決めるルールや戦略のことです。
強化学習の目的は、環境との試行錯誤を通して、このポリシーを改善し、最終的に「報酬の合計が最大になるような戦略」を自動的に学び取ることにあります。
ポリシーの2つのタイプ
ポリシーには大きく分けて「確率的ポリシー」と「決定的ポリシー」の2種類があります。
確率的ポリシー
これは、同じ状況でも複数の行動を確率的に選ぶタイプのポリシーです。
特徴としては
- 行動に“ゆらぎ”があるため探索を自然に行える
- 離散的な行動(例:前進・後退・ジャンプなど)が明確なタスクに向いている
- 方策勾配と呼ばれる手法と非常に相性が良い
強化学習では探索が非常に重要なので、確率的ポリシーは実用上よく使われます。
決定的ポリシー
これは、状況が決まれば行動が一意に決まるポリシーです。
特徴
- 連続的な行動(例:モーターの出力を0.0〜1.0で調整する)が必要なタスクで強い
- 確率を扱わないぶんシンプルで、高速に行動を決定できる
- 探索のためのノイズを外側で設計する必要がある
ロボット制御などでは、この決定的ポリシーを使う手法が多く採用されます。
ポリシーを学習する3つのアプローチ
RLアルゴリズムは、ポリシーそのもの、あるいはポリシーの裏側にある価値を改善することで戦略を良くしていきます。
アプローチは以下の3分類が代表的です。
価値ベース(Value-based)
代表例:Q-learning、DQN
- 状況ごとに「どの行動がどれくらい良いか(価値)」を学習する
- ポリシーはその価値を元に自動的に決まる(例:一番良い行動を選ぶ)
- 離散的な行動空間に強い
- ポリシー自体を直接学習しているわけではない
価値を最大化するよう行動を選ぶため、ポリシーは「価値の最大行動を選ぶルール」によって導かれます。
方策ベース(Policy-based)
代表例:REINFORCE、PPO
- ポリシーそのものをニューラルネットなどで直接表現し、そのパラメータを更新する
- 連続行動や確率的な行動選択を自然に扱える
- 勾配の計算が不安定になりやすく、その改善が多くの研究テーマになってきた
方策ベースは「戦略を直接学習する」という思想で、非常に柔軟です。
アクター・クリティック(Actor-Critic)
代表例:A2C、A3C、PPO、DDPG、SAC
ポリシー(Actor)と価値関数(Critic)を同時に学習するハイブリッド構造。
- Actor=行動を決める役
- Critic=その行動がどれだけ良かったかを評価する役
Critic が Actor を補助する形で学習を安定化するため、多くの実用的手法がこの構造を採用しています。
ポリシーがどのように更新されるか(直感的に理解)
強化学習におけるポリシー更新は、ひと言で言えば、「良い結果につながった行動を増やし、悪い結果につながった行動を減らす」という極めてシンプルな方針です。
このアイデアを数学的に厳密化したものが「方策勾配」などの手法であり、Critic を使うことでその“良さの評価”をより正確かつ安定させます。
代表的アルゴリズムとポリシーの扱いの違い
ここでは、主要アルゴリズムがポリシーをどう扱っているかを整理します。
REINFORCE
- ポリシーを直接改善しようとする最も基本的な手法
- シンプルだが揺らぎが大きく、学習が不安定になりやすい
PPO(Proximal Policy Optimization)
- ポリシーが「一度に変わりすぎないように抑制」する仕組みを持つ
- そのおかげで学習が非常に安定し、近年の標準的手法の一つとなった
A2C/A3C
- 複数のエージェントを並列に動かし効率よく学習
- Critic が Actor の学習をサポートして安定させる
- かつて多くのゲームAIで利用された
DDPG(Deep Deterministic Policy Gradient)
- 決定的ポリシーを使う代表的手法
- 連続行動に強い
- 外部ノイズで探索を工夫する必要がある
- 改良版としてTD3が存在
SAC(Soft Actor-Critic)
- ポリシーに“ゆらぎ”を意図的に持たせることで探索を促進
- 学習の安定性も高く、連続制御タスクで非常に強力
ポリシー設計で重要となる実務的ポイント
ポリシーが機能するためには、事前の設計が大きな役割を果たします。
行動空間の設計
行動の種類が多すぎると学習が困難になり、少なすぎると最適解にたどり着けません。
初期ポリシーの設定
連続行動では、初期段階で行動が大きくなりすぎると、探索が暴走し学習が破綻します。
そのため、ポリシーの出力が小さく始まるように調整することが多いです。
探索の仕組み
- 確率的ポリシー → 自然に探索できる
- 決定的ポリシー → 外部ノイズで工夫する必要がある
探索設計は強化学習の要ともいえる部分です。
急激なポリシー変更の防止
PPOに代表されるように、「ポリシーが一気に変わりすぎると学習が壊れる」ため、変化量を抑える仕組みが多く使われます。
まとめ:ポリシーとは「学習される戦略そのもの」
- ポリシーとは、状況に応じた行動選択のルール
- 確率的/決定的の2種類が存在
- 価値ベース・方策ベース・アクタークリティックの3系統が主流
- PPO、SAC、DDPG などはポリシーの扱い方が異なり、それぞれ長所がある
- 良いポリシーを得るには行動空間設計・探索ノイズ・安定化手法が重要
以上、強化学習ポリシーについてでした。
最後までお読みいただき、ありがとうございました。